https://www.youtube.com/watch?v=7GBXCD-B6fo
================================================================================
Which model (from model A and model B) is more precise?
 ================================================================================
Example of perfect prediction model
================================================================================
Example of perfect prediction model
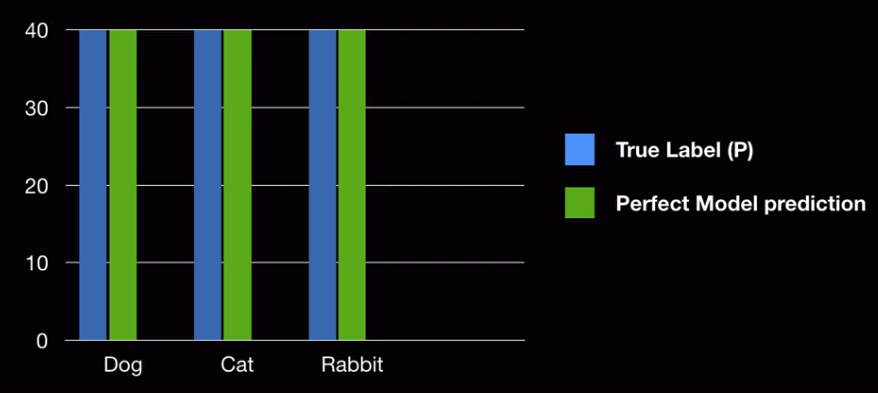 Difference of distibutions (distribution of label, distribution of prediction) is 0
================================================================================
Let's represent "difference of distribution" in numerical values
---> KL divergence
================================================================================
Model A's probability distribution about the prediction: $$$Q_A$$$
Model B's probability distribution about the prediction: $$$Q_B$$$
================================================================================
$$$D_{KL}(P||P) = 0.0$$$
$$$D_{KL}(P||Q_A) = 0.25$$$
$$$D_{KL}(P||Q_B) = 1.85$$$
================================================================================
Relative entropy:
Criterion: 90 score
Your score: 93 score
You have 3 scores more than criterion score
Relative entropy
= KL divergence
= "3 scores more than criterion score"
================================================================================
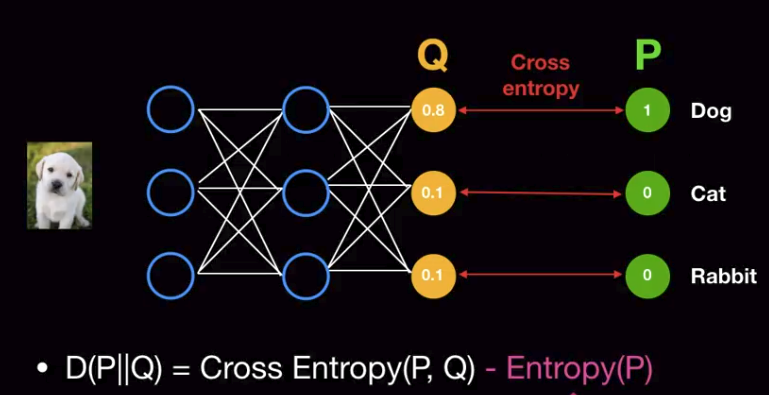
Cross Entropy(P,Q)
= exact_bits + extra_bits (uncertainty values) for storing information
Relative_Entropy
= D(P||Q)
= Cross_Entropy(P,Q) - Entropy(P)
= $$$-\sum\limits_{i=1}^{n} (p_i * \log_2{q_i}) + \sum\limits_{i=1}^{n} (p_i * \log_2{p_i})$$$
P: true label
Q: prediction (?)
================================================================================
$$$D(P||Q) \ge 0$$$
$$$D(P||Q) \ne D(Q||P)$$$
================================================================================
Why "KL divergence" is not used as loss function in deep learning?
Difference of distibutions (distribution of label, distribution of prediction) is 0
================================================================================
Let's represent "difference of distribution" in numerical values
---> KL divergence
================================================================================
Model A's probability distribution about the prediction: $$$Q_A$$$
Model B's probability distribution about the prediction: $$$Q_B$$$
================================================================================
$$$D_{KL}(P||P) = 0.0$$$
$$$D_{KL}(P||Q_A) = 0.25$$$
$$$D_{KL}(P||Q_B) = 1.85$$$
================================================================================
Relative entropy:
Criterion: 90 score
Your score: 93 score
You have 3 scores more than criterion score
Relative entropy
= KL divergence
= "3 scores more than criterion score"
================================================================================
Cross Entropy(P,Q)
= exact_bits + extra_bits (uncertainty values) for storing information
Relative_Entropy
= D(P||Q)
= Cross_Entropy(P,Q) - Entropy(P)
= $$$-\sum\limits_{i=1}^{n} (p_i * \log_2{q_i}) + \sum\limits_{i=1}^{n} (p_i * \log_2{p_i})$$$
P: true label
Q: prediction (?)
================================================================================
$$$D(P||Q) \ge 0$$$
$$$D(P||Q) \ne D(Q||P)$$$
================================================================================
Why "KL divergence" is not used as loss function in deep learning?
 - As training goes, weight values in the model changes
- Prediction Q will also change
- which means Cross_Entropy(P,Q) changes as training goes
- Entropy(P) is used as "constant"
- Therefore, there is no need to use "KL divergence" as loss function
- You can get same effect but with simpler loss function
- by using "cross entropy loss function"
- As training goes, weight values in the model changes
- Prediction Q will also change
- which means Cross_Entropy(P,Q) changes as training goes
- Entropy(P) is used as "constant"
- Therefore, there is no need to use "KL divergence" as loss function
- You can get same effect but with simpler loss function
- by using "cross entropy loss function"