https://datascienceschool.net/view-notebook/e6ef730b7a3b4be7be4ff028d39d67f7/
================================================================================
* $$$\hat{y}$$$ is expressed by linear combination
* $$$\hat{y} = w_1x_1 + w_2x_2 + \cdots + w_Nx_N$$$
* If all columns are linear independent,
$$$\hat{y}$$$ should be located in vector space
which has basis vector composed of each column of $$$c_1,\cdots,c_M$$$
================================================================================
$$$\hat{y}=X\omega$$$
* $$$X$$$: multiple feature vectors
* $$$\omega$$$: trainable parameters
* $$$\hat{y}$$$: prediction
$$$= [c_1, \cdots, c_M] \begin{bmatrix} \omega_1\\\vdots\\\omega_M \end{bmatrix}$$$
$$$= \omega_1c_1 + \cdots + \omega_Mc_M$$$
================================================================================
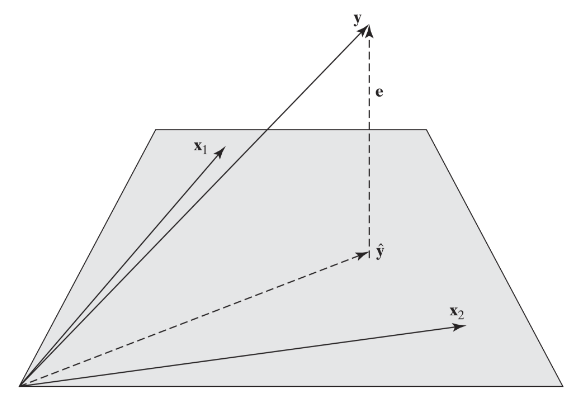
* Residual vector $$$\epsilon$$$
* $$$\epsilon = y-\hat{y}$$$
* $$$\hat{y}$$$ is vector which minimizes $$$\epsilon$$$,
which is nearest to $$$y$$$
* Residual vector $$$\epsilon$$$ $$$\perp$$$ vector space
* y_hat_vector,residual_vec=projection_to_vector_space(y_vector)
vector_space
basis_vectors=[c_1,...,c_M]
is_perp(vector_space,residual_vec)
# True
================================================================================
 ================================================================================
b=Ta
* Code
scope:linear vector space
transformed_vector_b=transform_mat*vector_a
================================================================================
$$$\epsilon = M y$$$
$$$\hat{y} = H y$$$
* Code
scope:linear vector space
residual_vec=transform_mat_M*label_vec_y
pred_vec_y=transform_mat_H*label_vec_y
================================================================================
$$$e
= y - \hat{y} \\
= y - Xw \\
= y - X(X^TX)^{-1}X^Ty \\
= (I - X(X^TX)^{-1}X^T)y \\
= My$$$
$$$M = I - X(X^TX)^{-1}X^T$$$
M: residual matrix
================================================================================
$$$\hat{y}
=y - e \\
=y - My \\
=(I - M)y \\
=X(X^TX)^{-1}X^T y \\
=Hy$$$
$$$H = X(X^TX)^{-1}X^T$$$
H: projection matrix, hat matrix, influence matrix
================================================================================
Characteristics of residual matrix and projection matrix
(1) Symetric matrix
$$$M^T=M$$$
$$$H^T=H$$$
inv(M)=M
inv(H)=H
(2) idempotent matrix
$$$M^2=M, M^3=M, \cdots$$$
$$$H^2=M, H^3=M, \cdots$$$
pow(M,2)=M
pow(M,3)=M
pow(H,2)=H
pow(H,3)=H
(3) M and H are perpendual
$$$MH=HM=0$$$
mul(M,H)==mul(H,M)==0
# True
(4) M and X are perpendual
$$$MX=0$$$
mul(M,X)==0
# True
(5) Multiply X by H doesn't change X
HX=X
================================================================================
Remember
$$$y^Ty = \hat{y}^T \hat{y}+ e^T e$$$
pow(y,2)=pow(pred_y,2)+pow(residual_vec,2)
================================================================================
b=Ta
* Code
scope:linear vector space
transformed_vector_b=transform_mat*vector_a
================================================================================
$$$\epsilon = M y$$$
$$$\hat{y} = H y$$$
* Code
scope:linear vector space
residual_vec=transform_mat_M*label_vec_y
pred_vec_y=transform_mat_H*label_vec_y
================================================================================
$$$e
= y - \hat{y} \\
= y - Xw \\
= y - X(X^TX)^{-1}X^Ty \\
= (I - X(X^TX)^{-1}X^T)y \\
= My$$$
$$$M = I - X(X^TX)^{-1}X^T$$$
M: residual matrix
================================================================================
$$$\hat{y}
=y - e \\
=y - My \\
=(I - M)y \\
=X(X^TX)^{-1}X^T y \\
=Hy$$$
$$$H = X(X^TX)^{-1}X^T$$$
H: projection matrix, hat matrix, influence matrix
================================================================================
Characteristics of residual matrix and projection matrix
(1) Symetric matrix
$$$M^T=M$$$
$$$H^T=H$$$
inv(M)=M
inv(H)=H
(2) idempotent matrix
$$$M^2=M, M^3=M, \cdots$$$
$$$H^2=M, H^3=M, \cdots$$$
pow(M,2)=M
pow(M,3)=M
pow(H,2)=H
pow(H,3)=H
(3) M and H are perpendual
$$$MH=HM=0$$$
mul(M,H)==mul(H,M)==0
# True
(4) M and X are perpendual
$$$MX=0$$$
mul(M,X)==0
# True
(5) Multiply X by H doesn't change X
HX=X
================================================================================
Remember
$$$y^Ty = \hat{y}^T \hat{y}+ e^T e$$$
pow(y,2)=pow(pred_y,2)+pow(residual_vec,2)