https://datascienceschool.net/view-notebook/6927b0906f884a67b0da9310d3a581ee/
================================================================================
* Bag of Words
* Word dictionary: "I", "am", "a", "boy", "girl"
* Word: index
"I":0
"am":1
"a":2
"boy":3
"girl":4
* Sentence to vector
"I am a girl" = [1 1 1 0 1]
================================================================================
* Word embedding: make a float values for one word in the text
* Following is 2D embedding example
* Word: 2D vector
"I":[0.3 0.2]
"am":[0.1 0.8]
"a":[0.5 0.6]
"boy":[0.2 0.9]
"girl":[0.4 0.7]
================================================================================
* Operation on word vectors to express one entire text
- Concatenation
- Averaging
================================================================================
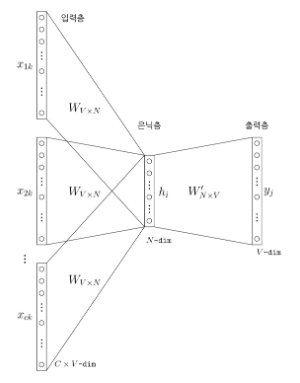
* Create word embedding
 * Suppose V number of words in dictionary
* One word is expressed by V-dim vector
* Encode input and output word by BOW way
* Perform one-hot-encoding on word vector x
* $$$h=\sigma(Wx)$$$
- $$$h$$$: hidden vector
- $$$W$$$: trainable parameter
- $$$x$$$: input word vector
* Suppose V number of words in dictionary
* One word is expressed by V-dim vector
* Encode input and output word by BOW way
* Perform one-hot-encoding on word vector x
* $$$h=\sigma(Wx)$$$
- $$$h$$$: hidden vector
- $$$W$$$: trainable parameter
- $$$x$$$: input word vector
 ================================================================================
* Embedding word vectors have following characteristics
================================================================================
* Embedding word vectors have following characteristics
 ================================================================================
NLP probelm
* single word context: one word is given, predict next word
* multi word context: words are given, predicts words
* Example,
- Target words: the quick brown fox jumped over the lazy dog
- When 3 words (the, quick, brown) are given, you need to predict "fox"
================================================================================
================================================================================
NLP probelm
* single word context: one word is given, predict next word
* multi word context: words are given, predicts words
* Example,
- Target words: the quick brown fox jumped over the lazy dog
- When 3 words (the, quick, brown) are given, you need to predict "fox"
================================================================================
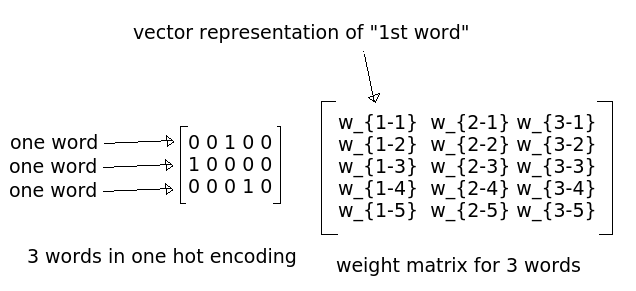
 * Embedding matrix is used in common for 3 input words
================================================================================
* Skip gram embedding
* one word is give, you predict words
================================================================================
* Word2vec
* Embedding matrix is used in common for 3 input words
================================================================================
* Skip gram embedding
* one word is give, you predict words
================================================================================
* Word2vec