This is note I wrote as I was take following lecture
http://www.kocw.net/home/search/kemView.do?kemId=1189957
- How_to_predict_likelihood_pdf_Parameter_estimation_Non_parameter_density_function_Maximum_likelihood_estimation
================================================================================
* So far, you've learned the way which classifies feature vector
"when you know likelihood (as PDF)"
================================================================================
* Then, how can you predict that likelihood PDF itself?
* For example, so far, you supposed you already know the probability distribution
of heights of male and female.
* But you actually don't know that probability distribution.
It means you should predict PDF from experiments and samples.
================================================================================
* Techniques to predict likelihood PDF:
1. Parameter Estimation:
* You'll suppose the assumption that PDF will have specific shape
(like Gaussian shape specifically)
* Mean and variance are core elements which define Gaussian shape
* Parameter Estimation finds mean and variance of Gaussian distribution
by using Maximum Likelihood Estimation
* Code
mean,variance=maximum_likelihood_estimation(sample_data)
2. Non-parametric Density Estimation
* You won't suppose the assumption that PDF will not have specific shape
* Non-parametric Density Estimation just predicts likelihood PDF from data
* Kernel Density Esitimation, K Nearest Neighbor Estimation, etc
* Code
likelihood_PDF=non_parametric_density_estimation(sample_data)
================================================================================
* Maximum Likelihood Estimation (MLE)
* It's the way which finds likelihood PDF by selecting best proper mean and variance
================================================================================
 * X: feature vector like heights
* There should be population which generates feature vectors
* What you want to do is to find the parameters which defines the shape of that population.
* $$$\theta_1$$$: parameters which defines candidate population 1
* $$$\theta_2$$$: parameters which defines candidate population 2
* $$$P(X|\theta_1)$$$: probability of X occuring from population 1 which is defined by $$$\theta_1$$$
* $$$P(X|\theta_2)$$$: probability of X occuring from population 2 which is defined by $$$\theta_2$$$
================================================================================
* Besides, other population and its corresponding $$$\theta$$$ can exist
* X: feature vector like heights
* There should be population which generates feature vectors
* What you want to do is to find the parameters which defines the shape of that population.
* $$$\theta_1$$$: parameters which defines candidate population 1
* $$$\theta_2$$$: parameters which defines candidate population 2
* $$$P(X|\theta_1)$$$: probability of X occuring from population 1 which is defined by $$$\theta_1$$$
* $$$P(X|\theta_2)$$$: probability of X occuring from population 2 which is defined by $$$\theta_2$$$
================================================================================
* Besides, other population and its corresponding $$$\theta$$$ can exist
 ================================================================================
* Then, you get this each probabiity of X occuring
when each $$$\theta$$$ (each population) is given
================================================================================
* Then, you get this each probabiity of X occuring
when each $$$\theta$$$ (each population) is given
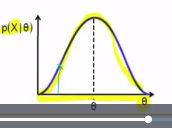 * $$$p(X|\theta)$$$: probability value of $$$X$$$ occuring from populations which are defined $$$\theta$$$
* $$$\hat{\theta} = \arg_{\theta} \max[p(X|\theta)]$$$
* $$$\hat{\theta}$$$: parameters $$$\theta$$$ which is best preper to define population
================================================================================
* How to find above best proper $$$\theta$$$
* Maximum likelihood function
$$$\hat{\theta} = \arg_{\theta} \max P(X|\theta)$$$
* $$$p(X|\theta)$$$: probability value of $$$X$$$ occuring from populations which are defined $$$\theta$$$
* $$$\hat{\theta} = \arg_{\theta} \max[p(X|\theta)]$$$
* $$$\hat{\theta}$$$: parameters $$$\theta$$$ which is best preper to define population
================================================================================
* How to find above best proper $$$\theta$$$
* Maximum likelihood function
$$$\hat{\theta} = \arg_{\theta} \max P(X|\theta)$$$