This is notes which I wrote as I was taking video lecture originated from
https://www.youtube.com/watch?v=AFIO92N9xm4&list=PLbhbGI_ppZISMV4tAWHlytBqNq1-lb8bz
================================================================================
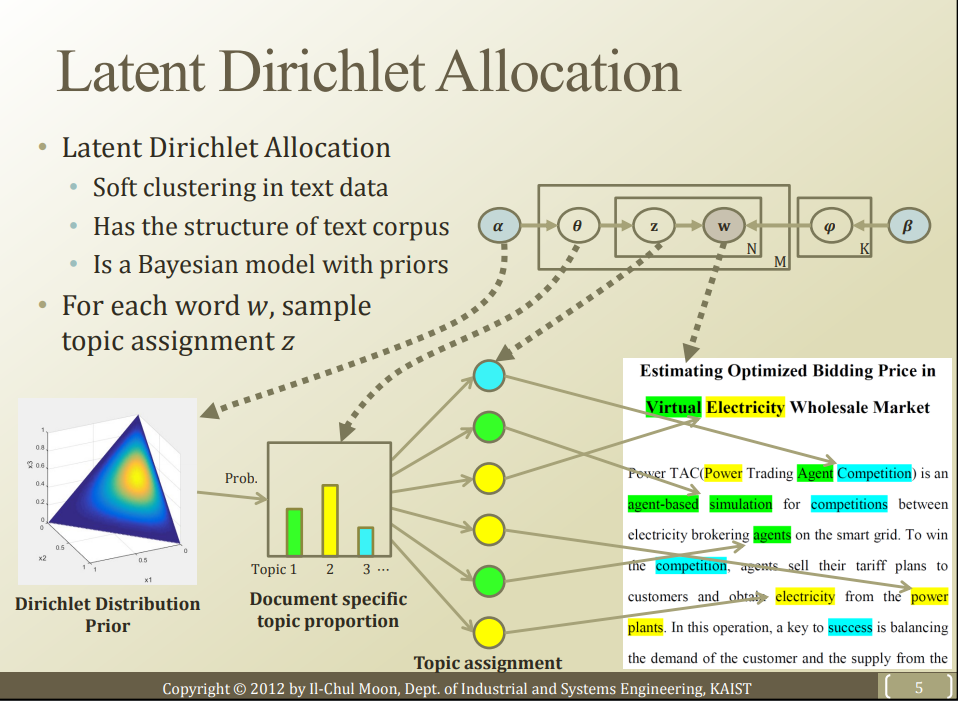 ================================================================================
w: observation, words
z: you assign "words" into cluster by using z
word --z--> topic
$$$z$$$ is modeled by Multinomial distribution
N: number of entire words in one document (for example, 100 words in one document)
M: number of entire documents (for example, 10 documents)
$$$\theta$$$: document --$$$\theta$$$ --> topic
$$$\theta$$$ is modeled by Multinomial distribution
$$$\alpha$$$: prior for $$$\theta$$$
$$$\alpha$$$ is modeld by Dirichlet distribution (with respect to $$$\theta$$$)
$$$K$$$: number of topic which user can configure
$$$\phi$$$: probability of "word" showing in each topic
$$$\beta$$$: prior knowledge
================================================================================
================================================================================
w: observation, words
z: you assign "words" into cluster by using z
word --z--> topic
$$$z$$$ is modeled by Multinomial distribution
N: number of entire words in one document (for example, 100 words in one document)
M: number of entire documents (for example, 10 documents)
$$$\theta$$$: document --$$$\theta$$$ --> topic
$$$\theta$$$ is modeled by Multinomial distribution
$$$\alpha$$$: prior for $$$\theta$$$
$$$\alpha$$$ is modeld by Dirichlet distribution (with respect to $$$\theta$$$)
$$$K$$$: number of topic which user can configure
$$$\phi$$$: probability of "word" showing in each topic
$$$\beta$$$: prior knowledge
================================================================================
 ================================================================================
================================================================================
 $$$\alpha$$$: topics Dirichlet distribution with respect to entire corpus
Multinomial distibution $$$\theta$$$ is generated from Dirichlet distribution prior $$$\alpha$$$
================================================================================
$$$\alpha$$$: topics Dirichlet distribution with respect to entire corpus
Multinomial distibution $$$\theta$$$ is generated from Dirichlet distribution prior $$$\alpha$$$
================================================================================
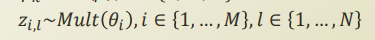 ================================================================================
================================================================================
 ================================================================================
================================================================================
 ================================================================================
================================================================================