| 1000 pics in total | Model predicted it's non-tumor | Model predicted it's tumor |
| On non-tumor pics | 988 (True Negative) | 2 (False Positive) |
| On tumor pics | 1 (False Negative) | 9 (True Positive) |
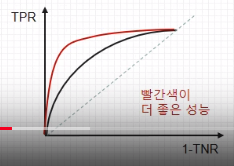
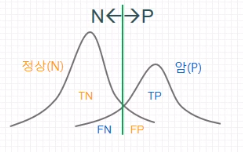
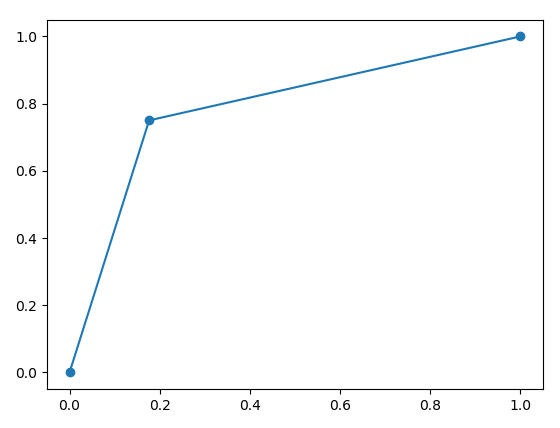
# ================================================================================ # @ 1. Calculate confusion matrix from sklearn.metrics import confusion_matrix y_true=[0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0] y_pred=[0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0] c_mat=confusion_matrix(y_true,y_pred,labels=[1,0]) print(c_mat) # [[24 8] # [12 56]] # ================================================================================ # @ 2. Calculate various metrics using classification_report() from sklearn.metrics import classification_report classification_report_result=classification_report( y_true,y_pred,target_names=['class Non tumor (neg)','class Tumor (pos)']) print("classification_report_result",classification_report_result) # precision recall f1-score support # class Non tumor (neg) 0.88 0.82 0.85 68 # class Tumor (pos) 0.67 0.75 0.71 32 # micro avg 0.80 0.80 0.80 100 # macro avg 0.77 0.79 0.78 100 # weighted avg 0.81 0.80 0.80 100 # ================================================================================ # @ 3. Calculate metrics one by one from sklearn.metrics import accuracy_score,precision_score, recall_score,fbeta_score,f1_score print("accuracy_score",accuracy_score(y_true,y_pred).astype("float16")) # 0.8 print("precision_score",precision_score(y_true,y_pred).astype("float16")) # 0.6665 print("recall_score",recall_score(y_true,y_pred).astype("float16")) # 0.75 # print("fbeta_score",fbeta_score(y_true, y_pred, beta)) print("f1_score",fbeta_score(y_true,y_pred,beta=1).astype("float16")) # 0.706 # ================================================================================ # @ 4. Calculate ROC curve from sklearn.metrics import roc_curve import matplotlib.pyplot as plt fpr,tpr,thresholds=roc_curve(y_true,y_pred) plt.plot(fpr,tpr,'o-') plt.show()
# @ Calculate metrics manually import numpy as np y_true_np=np.array(y_true) y_pred_np=np.array(y_pred) # ================================================================================ mask_for_diff=y_pred_np!=y_true_np y_true_diff_against_y_pred=y_true_np[mask_for_diff] y_pred_diff_against_y_true=y_pred_np[mask_for_diff] # print(y_true_diff_against_y_pred) # [0 0 0 1 0 1 1 1 0 1 0 0 0 0 1 0 1 1 0 0] # print(y_pred_diff_against_y_true) # [1 1 1 0 1 0 0 0 1 0 1 1 1 1 0 1 0 0 1 1] num_of_what_pred_said_1_incorrectly_in_diff_cases=np.sum((y_pred_diff_against_y_true==1).astype("uint8")) num_of_what_pred_said_0_incorrectly_in_diff_cases=np.sum((y_pred_diff_against_y_true==0).astype("uint8")) # print(num_of_what_pred_said_1_incorrectly_in_diff_cases) # 12 # print(num_of_what_pred_said_0_incorrectly_in_diff_cases) # 8 # ================================================================================ mask_for_same=y_pred_np==y_true_np y_pred_same_against_y_true=y_pred_np[mask_for_same] y_true_same_against_y_pred=y_true_np[mask_for_same] # print(y_pred_same_against_y_true) # [0 0 0 1 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 1 0 0 1 0 0 0 1 0 1 0 1 1 1 # 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 1 0 1 0 1 0 0 1 0 0 # 0 1 0 0 0 0] # print(y_true_same_against_y_pred) # [0 0 0 1 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 1 0 0 1 0 0 0 1 0 1 0 1 1 1 # 0 0 1 0 0 0 1 0 1 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 0 1 0 1 0 1 0 1 0 0 1 0 0 # 0 1 0 0 0 0] num_of_what_pred_said_1_correctly_in_same_cases=np.sum((y_pred_same_against_y_true==1).astype("uint8")) num_of_what_pred_said_0_correctly_in_same_cases=np.sum((y_pred_same_against_y_true==0).astype("uint8")) # print(num_of_what_pred_said_1_correctly_in_same_cases) # 24 # print(num_of_what_pred_said_0_correctly_in_same_cases) # 56 # ================================================================================ # @ 5. Calculate binary confusion matrix manually True_Positive=num_of_what_pred_said_1_correctly_in_same_cases False_Positive=num_of_what_pred_said_0_incorrectly_in_diff_cases False_Negative=num_of_what_pred_said_1_incorrectly_in_diff_cases True_Negative=num_of_what_pred_said_0_correctly_in_same_cases confusion_mat=[ [True_Positive,False_Positive], [False_Negative,True_Negative]] print(confusion_mat) # [[24, 8], # [12, 56]] # ================================================================================ # @ 6. Calculate accuracy, precision, recall manually # (1) Accuracy accracy=(True_Positive+True_Negative)/(True_Positive+False_Positive+False_Negative+True_Negative) print(accracy.astype("float16")) # 0.8 # (2) Precision precision=True_Positive/(True_Positive+False_Positive) print(precision.astype("float16")) # 0.75 # (2) Recall recall=True_Positive/(True_Positive+False_Negative) print(recall.astype("float16")) # 0.6665