================================================================================
https://ratsgo.github.io/natural%20language%20processing/2017/10/22/manning/
/mnt/1T-5e7/mycodehtml/NLP/Bi_LSTM/Ratsgo/main.html
================================================================================
Vanilla RNN
- Weak for gradient vanishing/exploding
- Why?
-  - To find gradient at $$$h_1$$$, you should use chain rule
================================================================================
How to solve "gradient vanishing/exploding"?
- LSTM which has "gates"
- "gates" adds "previous information" and "current information"
- Then, gradient can flow well
================================================================================
Vanilla Seq2Seq
- To find gradient at $$$h_1$$$, you should use chain rule
================================================================================
How to solve "gradient vanishing/exploding"?
- LSTM which has "gates"
- "gates" adds "previous information" and "current information"
- Then, gradient can flow well
================================================================================
Vanilla Seq2Seq
 - Encoder: creates vectors from input sentence
- Decoder: converts vector to target sentence
- Encoder and Decoder: LSTM
================================================================================
Weakness of vanilla Seq2Seq
- Longer input sentence
- Deeper encoder
- Encoder should compress "too much of information"
- Encoder causes "loss of information"
- Most meaningful input data is paid attention to by using attention mechanism
================================================================================
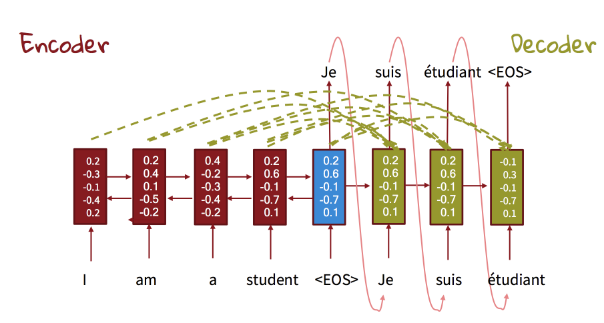
- Bidirectional network: sees input sentence from L to R, from R to L
================================================================================
BiLSTM+LSTM cell in decoder+attention
- Encoder: creates vectors from input sentence
- Decoder: converts vector to target sentence
- Encoder and Decoder: LSTM
================================================================================
Weakness of vanilla Seq2Seq
- Longer input sentence
- Deeper encoder
- Encoder should compress "too much of information"
- Encoder causes "loss of information"
- Most meaningful input data is paid attention to by using attention mechanism
================================================================================
- Bidirectional network: sees input sentence from L to R, from R to L
================================================================================
BiLSTM+LSTM cell in decoder+attention
 ================================================================================
The reason that Bi-LSTM has good performance
- End to end learning: when reducing loss wrt predicted output,
all trainable params are updated at the same time
- Use distributed representation:
Relationship between "word" and "phrase" in inserted into word-vector
- Use LSTM, attention:
even with long sentence, performance doesn't degraded
================================================================================
Stanford Attentive Reader (2016)
- It finds the "answer" wrt to "given question" in the context of text
- It uses BiLSTM with attention
================================================================================
p_vector=Bidirectional_encoder1(text_paragraph)
q_vector=Bidirectional_encoder2(question)
$$$\alpha_i$$$: attention score of ith word in text_paragraph
$$$\alpha_i = softmax(q^T W p_i) $$$
================================================================================
output_vector_o=Decoder(alpha,p)
output_vector_o
$$$= alpha_1 p_1 + alpha_2 p_2 + \cdots $$$
$$$= \sum\limits_{i} \alpha_i p_i$$$
================================================================================
loss_val=loss_func(output_vector_o,gt)
================================================================================
================================================================================
The reason that Bi-LSTM has good performance
- End to end learning: when reducing loss wrt predicted output,
all trainable params are updated at the same time
- Use distributed representation:
Relationship between "word" and "phrase" in inserted into word-vector
- Use LSTM, attention:
even with long sentence, performance doesn't degraded
================================================================================
Stanford Attentive Reader (2016)
- It finds the "answer" wrt to "given question" in the context of text
- It uses BiLSTM with attention
================================================================================
p_vector=Bidirectional_encoder1(text_paragraph)
q_vector=Bidirectional_encoder2(question)
$$$\alpha_i$$$: attention score of ith word in text_paragraph
$$$\alpha_i = softmax(q^T W p_i) $$$
================================================================================
output_vector_o=Decoder(alpha,p)
output_vector_o
$$$= alpha_1 p_1 + alpha_2 p_2 + \cdots $$$
$$$= \sum\limits_{i} \alpha_i p_i$$$
================================================================================
loss_val=loss_func(output_vector_o,gt)
================================================================================
 ================================================================================
Stanford Attentive Reader (2017)
- Same with Stanford Attentive Reader (2016)
- Added part: extracting "paragraph" from the long text
================================================================================
Stanford Attentive Reader (2017)
- Same with Stanford Attentive Reader (2016)
- Added part: extracting "paragraph" from the long text
 ================================================================================
Copy augmented S2S (2017)
- Copy words which have high attention score $$$\alpha$$$
- Paste copied words into "decoder"
out_vec_enco,words_with_high_attention_scores=Copy_augmented_S2S_2017_Encoder(question)
out_sentence=Copy_augmented_S2S_2017_Decoder(out_vec_enco,words_with_high_attention_scores)
================================================================================
================================================================================
Copy augmented S2S (2017)
- Copy words which have high attention score $$$\alpha$$$
- Paste copied words into "decoder"
out_vec_enco,words_with_high_attention_scores=Copy_augmented_S2S_2017_Encoder(question)
out_sentence=Copy_augmented_S2S_2017_Decoder(out_vec_enco,words_with_high_attention_scores)
================================================================================
 Question
Question
 Italian has high attention score
Italian is pasted into decoder_sentence
================================================================================
Tree based models (2015)
LSTM
Italian has high attention score
Italian is pasted into decoder_sentence
================================================================================
Tree based models (2015)
LSTM
 Tree based model
Tree based model
 ================================================================================
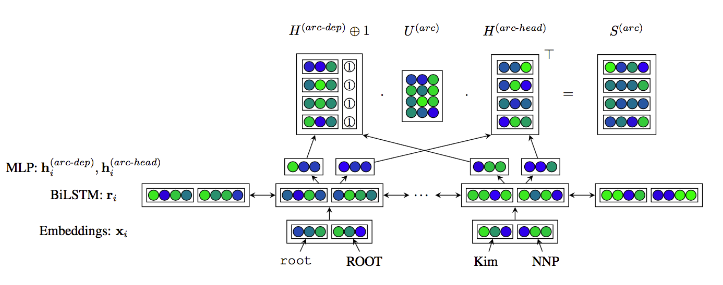
Dozat&Manning(2017) applies "BiLSTM with attention" into dependency parsing
================================================================================
Dozat&Manning(2017) applies "BiLSTM with attention" into dependency parsing