https://ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/20/docsim/
/mnt/1T-5e7/mycodehtml/NLP/Document_similarity/Ratsgo/main.html
================================================================================
Similarity: subjective
- Similarity between 2 entities increase when 2 entities share common attributes
- Each attribute is independent and addable
- Suppose "one document has one entity"
"One document" is composed of 5 variables
5 variables are independent (or uncorrelated) to each other
If you plot this document onto "vector space"
"basis" of each variable is perpendual
- You can add the variable up to 6, 7, ...
- Abstract level which each attribute has should be identical
Variable1: car
Variable2: BMW
this is not correct
Correct case should be
Variable1: car
Variable2: airplane
- Similarity should be enough to explain the "conceptual structure"
================================================================================
- If 2 document has many common words, 2 documents have high similarity
================================================================================
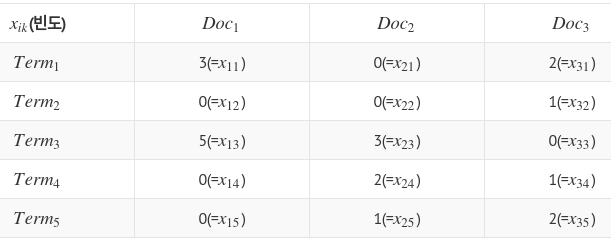
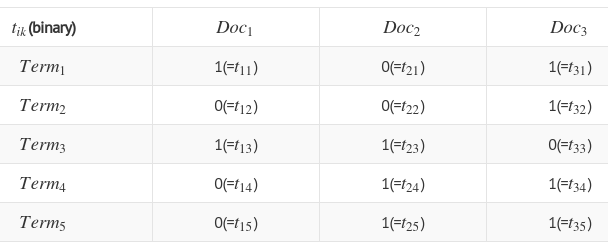
Notation explanation
$$$x_{ik}$$$: ith document, kth word, how many times word shows?
$$$t_{ik}$$$: 1 if $$$x_{ik}>0$$$, 0 otherwise
================================================================================
 ================================================================================
================================================================================
 ================================================================================
================================================================================
 - Meaning
- $$$b_{12}=1$$$, find the word which shows in Doc1, which not shows in Doc2,
it's Term1, so $$$b_{12}=1$$$
- $$$c_{12}=2$$$, find the word which not shows in Doc1, which shows in Doc2,
they're Term4, Term5, so $$$c_{12}=2$$$
- $$$a_{12}=2$$$, find the word which shows in Doc1, which shows in Doc2,
they're Term3, so $$$a_{12}=2$$$
- $$$d_{22}=2$$$, find the word which not shows in Doc1, which not shows in Doc2,
they're Term2, so $$$d_{22}=2$$$
================================================================================
Common features model
$$$\dfrac{\text{common_words_in_ith_doc_and_jth_doc}}{\text{number_of_entire_words}}$$$
$$$d_{ij}$$$: word which not shows in Doc_i, which not shows in Doc_j
Very large value because 2 documents have only small number of words
- Meaning
- $$$b_{12}=1$$$, find the word which shows in Doc1, which not shows in Doc2,
it's Term1, so $$$b_{12}=1$$$
- $$$c_{12}=2$$$, find the word which not shows in Doc1, which shows in Doc2,
they're Term4, Term5, so $$$c_{12}=2$$$
- $$$a_{12}=2$$$, find the word which shows in Doc1, which shows in Doc2,
they're Term3, so $$$a_{12}=2$$$
- $$$d_{22}=2$$$, find the word which not shows in Doc1, which not shows in Doc2,
they're Term2, so $$$d_{22}=2$$$
================================================================================
Common features model
$$$\dfrac{\text{common_words_in_ith_doc_and_jth_doc}}{\text{number_of_entire_words}}$$$
$$$d_{ij}$$$: word which not shows in Doc_i, which not shows in Doc_j
Very large value because 2 documents have only small number of words
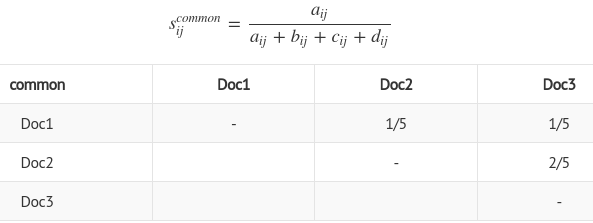 Similarity between Doc3 and Doc2 is high
================================================================================
ratio model
Without $$$d_{ij}$$$ from common features model
Similarity between Doc3 and Doc2 is high
================================================================================
ratio model
Without $$$d_{ij}$$$ from common features model
 ================================================================================
simple matching coefficient
Use $$$d_{ij}$$$ for upper and lower parts from "common features model"
================================================================================
simple matching coefficient
Use $$$d_{ij}$$$ for upper and lower parts from "common features model"
 ================================================================================
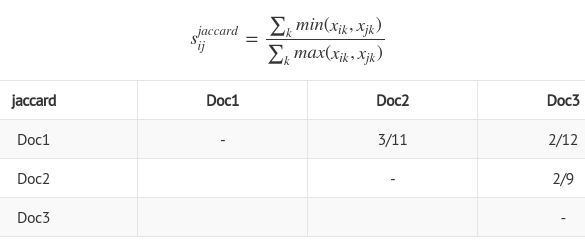
jaccard similarity
This is basically similar metric to "ratio model"
================================================================================
jaccard similarity
This is basically similar metric to "ratio model"
 ================================================================================
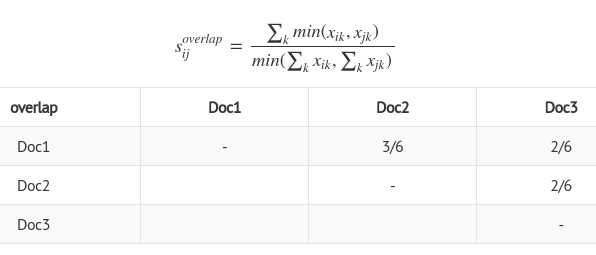
overlap similarity
================================================================================
overlap similarity
 ================================================================================
cosine similarity
Most used way to calculate similarity
================================================================================
cosine similarity
Most used way to calculate similarity
 ================================================================================
Conversation
Question:
- Word2Vec can be used to compare "Doc1" and "Doc2"?
- Planed model:
- Get new URL from the client
- Crawl that new URL and extract keywords from the news text
- Search "all news companies" by using extracted keywords
- Get similar "news text"
- Give similar "news text" to the client
Answer
- To calculate similarity between "Doc1" and "Doc2",
Word2Vec is not much good
- W2V converts "word" into "vector"
- But "vector" doesn't directly become "document"
- So, Doc2Vec is suggested
- Doc2Vec:
- Perform Word2Vec
- Each document has ID, ID of each document is converted itno vector
- Vector version documents can be calculated by "cosine similarity"
- Doc2Vec is included in gensim
https://radimrehurek.com/gensim/models/doc2vec.html
- But D2V abstract "document ID" too much,
so actual embedding performance is not that good
- So, using LSA can be another good choice
- Step
- Create Term-Document-Matrix from all corpus and all documents
- Perform SVD to convert "document" to "vector"
- "Document vectors" can be calculated by "cosine similarity"
ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/06/pcasvdlsa/
Additionally, summary of news text is mainly inclued in the title text
So, graph based analysis can be also good
ratsgo.github.io/natural%20language%20processing/2017/03/13/graphnews/
================================================================================
Conversation
Question:
- Word2Vec can be used to compare "Doc1" and "Doc2"?
- Planed model:
- Get new URL from the client
- Crawl that new URL and extract keywords from the news text
- Search "all news companies" by using extracted keywords
- Get similar "news text"
- Give similar "news text" to the client
Answer
- To calculate similarity between "Doc1" and "Doc2",
Word2Vec is not much good
- W2V converts "word" into "vector"
- But "vector" doesn't directly become "document"
- So, Doc2Vec is suggested
- Doc2Vec:
- Perform Word2Vec
- Each document has ID, ID of each document is converted itno vector
- Vector version documents can be calculated by "cosine similarity"
- Doc2Vec is included in gensim
https://radimrehurek.com/gensim/models/doc2vec.html
- But D2V abstract "document ID" too much,
so actual embedding performance is not that good
- So, using LSA can be another good choice
- Step
- Create Term-Document-Matrix from all corpus and all documents
- Perform SVD to convert "document" to "vector"
- "Document vectors" can be calculated by "cosine similarity"
ratsgo.github.io/from%20frequency%20to%20semantics/2017/04/06/pcasvdlsa/
Additionally, summary of news text is mainly inclued in the title text
So, graph based analysis can be also good
ratsgo.github.io/natural%20language%20processing/2017/03/13/graphnews/