https://ratsgo.github.io/natural%20language%20processing/2017/03/22/lexicon/
/mnt/1T-5e7/mycodehtml/NLP/Lexical_analysis/Ratsgo/main.html
================================================================================
NLP
 ================================================================================
Linguistics = Phonology + Morphology + Syntax + Semantics
================================================================================
Phonology
- researches voice
================================================================================
Linguistics = Phonology + Morphology + Syntax + Semantics
================================================================================
Phonology
- researches voice
 ================================================================================
Morphology
- researches "word" and "morphim"
================================================================================
Morphology
- researches "word" and "morphim"
 ================================================================================
Syntax
- researches grammar
================================================================================
Syntax
- researches grammar
 ================================================================================
Semantics
- researches contextual information
================================================================================
Semantics
- researches contextual information
 ================================================================================
NLP in computer
================================================================================
NLP in computer
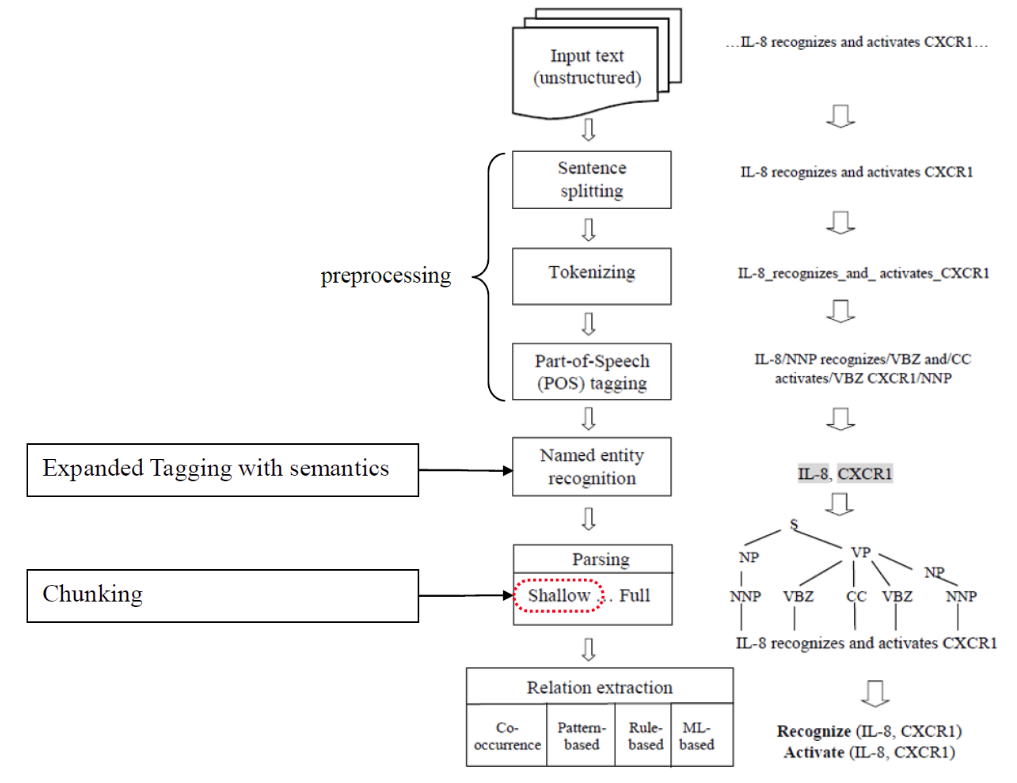 ================================================================================
Lexical Analysis step
================================================================================
Lexical Analysis step
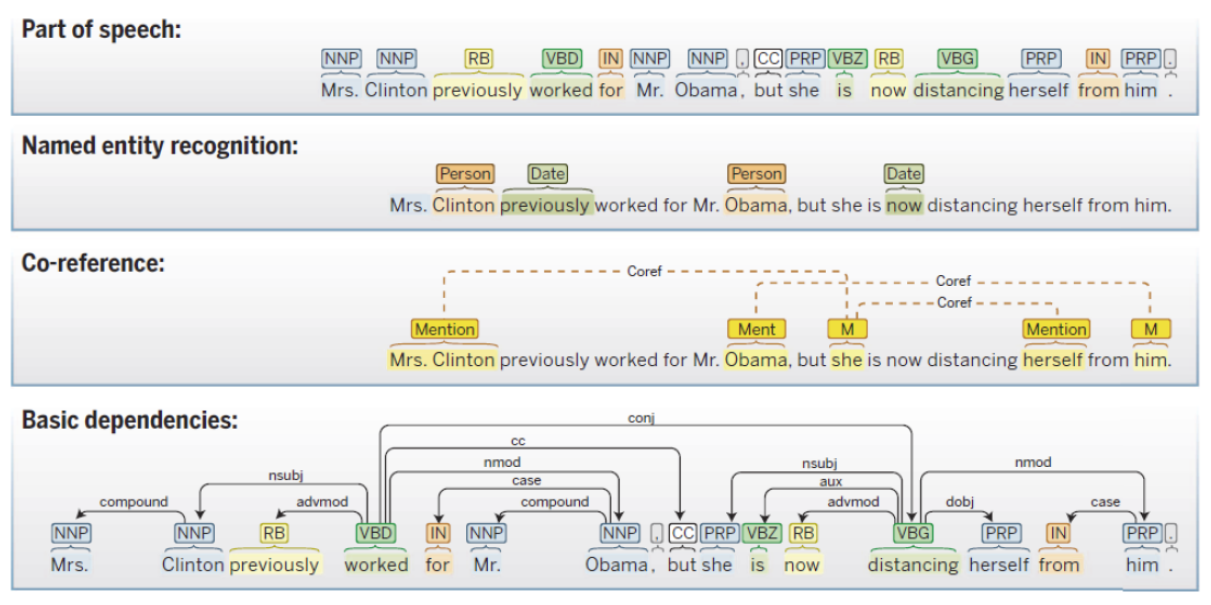 ================================================================================
POS(Part Of Speech) tagging
"Word": "POS"
================================================================================
NER(Named Entity Recognition)
Classify "unique noun"
================================================================================
Co-reference
Compares "previous word and phrase" to "current word and phrasee"
Are they same entity?
================================================================================
Basic dependencies
Unlike the previous method where it analyzes sentence by using element of each word (gramatically),
basic dependencies uses dependent relationship between words,
to analyze sentence
================================================================================
================================================================================
POS(Part Of Speech) tagging
"Word": "POS"
================================================================================
NER(Named Entity Recognition)
Classify "unique noun"
================================================================================
Co-reference
Compares "previous word and phrase" to "current word and phrasee"
Are they same entity?
================================================================================
Basic dependencies
Unlike the previous method where it analyzes sentence by using element of each word (gramatically),
basic dependencies uses dependent relationship between words,
to analyze sentence
================================================================================
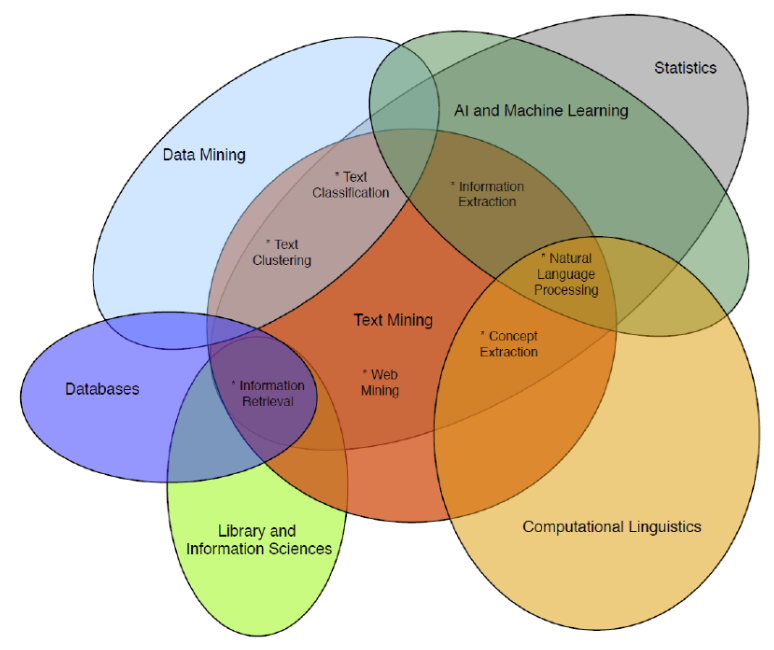 ================================================================================
Lexical analysis
- Sentence splitting
- Tokenize
- morphological analysis
- POS tagging
================================================================================
Case1: sentence splitting is required
Case2: sentence splitting is optional (topic modeling case)
Before sentence spliting: sentence_a. sentence_b. sentence_c?
After sentence splitting: [sentence_a.], [sentence_b.], [sentence_c?]
================================================================================
Tokenize
Morphim $$$\subset$$$ Word $$$\subset$$$ Token
Tokenize method:
- English: generally simply use "white space"
================================================================================
Morphological analysis (Text normalization)
Tokens --are converted into--> more general form
And you get "reduced number of tokens" to get more analysis efficiency
- Example
cars ---> car
car ---> car
stopped ---> stop
stop ---> stop
- Do "folding" (lower case)
Hello ---> hello
hello ---> hello
- Do "stemming"
Convert "word" into "short format"
- Do "lemmatization"
Convert "word" into the basic form which has POS information
================================================================================
================================================================================
Lexical analysis
- Sentence splitting
- Tokenize
- morphological analysis
- POS tagging
================================================================================
Case1: sentence splitting is required
Case2: sentence splitting is optional (topic modeling case)
Before sentence spliting: sentence_a. sentence_b. sentence_c?
After sentence splitting: [sentence_a.], [sentence_b.], [sentence_c?]
================================================================================
Tokenize
Morphim $$$\subset$$$ Word $$$\subset$$$ Token
Tokenize method:
- English: generally simply use "white space"
================================================================================
Morphological analysis (Text normalization)
Tokens --are converted into--> more general form
And you get "reduced number of tokens" to get more analysis efficiency
- Example
cars ---> car
car ---> car
stopped ---> stop
stop ---> stop
- Do "folding" (lower case)
Hello ---> hello
hello ---> hello
- Do "stemming"
Convert "word" into "short format"
- Do "lemmatization"
Convert "word" into the basic form which has POS information
================================================================================
 ================================================================================
POS tagging
Assing "POS" into each "token"
- Techniques
- Decision Trees
- Hidden Markov Model
- SVM
================================================================================
NLTK, spaCY perform the step of "sentence spliting, tokenization, lemmatization, POS tagging"
================================================================================
================================================================================
POS tagging
Assing "POS" into each "token"
- Techniques
- Decision Trees
- Hidden Markov Model
- SVM
================================================================================
NLTK, spaCY perform the step of "sentence spliting, tokenization, lemmatization, POS tagging"
================================================================================