https://www.slideshare.net/deepseaswjh/rnn-bert
================================================================================
RNN
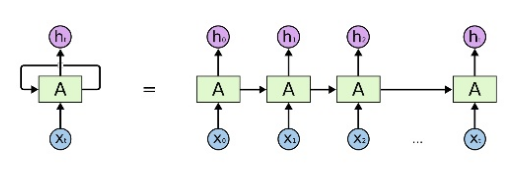 - $$$x_0, x_1, x_2, \cdots$$$: input tokens like I, go, to, ...
- 2 arrows from cells which are marked by "A": outputs
- Meaning
- Output from previous cell affect the training continuously
================================================================================
There are 2 trainable weights; W (for recurrent layers) and U (for input layers)
https://medium.com/deep-math-machine-learning-ai/chapter-10-deepnlp-recurrent-neural-networks-with-math-c4a6846a50a2
- $$$x_0, x_1, x_2, \cdots$$$: input tokens like I, go, to, ...
- 2 arrows from cells which are marked by "A": outputs
- Meaning
- Output from previous cell affect the training continuously
================================================================================
There are 2 trainable weights; W (for recurrent layers) and U (for input layers)
https://medium.com/deep-math-machine-learning-ai/chapter-10-deepnlp-recurrent-neural-networks-with-math-c4a6846a50a2
 ================================================================================
================================================================================
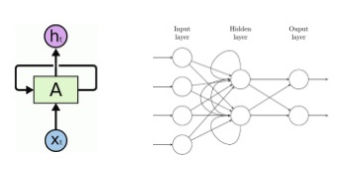 $$$a^{(t)} = b+W h^{(t-1)} + Ux^{(t)}$$$
$$$a^{(t)}$$$: output at time t
$$$b$$$: bias
$$$W$$$: trainable parameter for recurrent layers
$$$h^{(t-1)}$$$: output from previous cell
$$$x^{(t)}$$$: input data at time t
$$$U$$$: trainable parameter for input layers
$$$h^{(t)}=tanh(a^{(t)})$$$
$$$tanh()$$$: activation function
$$$h^{(t)}$$$: output from the cells
$$$o^{(t)}=c+Vh^{(t)}$$$
$$$o^{(t)}$$$: output in the last output layer
$$$y^{(t)}=softmax(o^{(t)})$$$: output in the last output layer after softmax
================================================================================
Various RNN structures
$$$a^{(t)} = b+W h^{(t-1)} + Ux^{(t)}$$$
$$$a^{(t)}$$$: output at time t
$$$b$$$: bias
$$$W$$$: trainable parameter for recurrent layers
$$$h^{(t-1)}$$$: output from previous cell
$$$x^{(t)}$$$: input data at time t
$$$U$$$: trainable parameter for input layers
$$$h^{(t)}=tanh(a^{(t)})$$$
$$$tanh()$$$: activation function
$$$h^{(t)}$$$: output from the cells
$$$o^{(t)}=c+Vh^{(t)}$$$
$$$o^{(t)}$$$: output in the last output layer
$$$y^{(t)}=softmax(o^{(t)})$$$: output in the last output layer after softmax
================================================================================
Various RNN structures
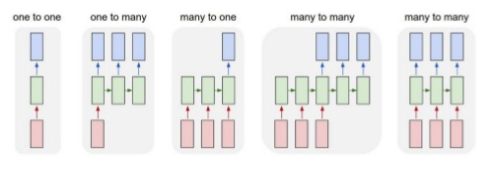 - Red: input structure
- Green: hidden structure
- Blue: output structure
================================================================================
LSTM (Long Shot Term Momory)
- Red: input structure
- Green: hidden structure
- Blue: output structure
================================================================================
LSTM (Long Shot Term Momory)
 - Intensity of data becomes vague as training goes
================================================================================
- Intensity of data becomes vague as training goes
================================================================================
 LSTM memorizes "important data" up to the end of training
================================================================================
LSTM memorizes "important data" up to the end of training
================================================================================
 - LSTM means "specially designed RNN cell"
- LSTM has 8 trainable parameters (4 for recurrent layers + 4 for input layers)
================================================================================
Weakness of RNN
- RNN considers only "previous status" + "current status"
- RNN doesn't consider "entire context" in the training
================================================================================
Seq2Seq to overcome weakness of RNN
- LSTM means "specially designed RNN cell"
- LSTM has 8 trainable parameters (4 for recurrent layers + 4 for input layers)
================================================================================
Weakness of RNN
- RNN considers only "previous status" + "current status"
- RNN doesn't consider "entire context" in the training
================================================================================
Seq2Seq to overcome weakness of RNN
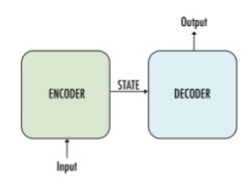 - Seq2Seq = Encoder_LSTM + Decoder_LSTM
================================================================================
Structure of Seq2Seq
- Seq2Seq = Encoder_LSTM + Decoder_LSTM
================================================================================
Structure of Seq2Seq
 - Step1: process "input sentence" by encoder, creating "feature vector"
- Step2: process "feature vector" by decoder, creating "output sentence"
================================================================================
Weakness of LSTM driven Seq2Seq
- It's lack of capability with only "gates" which adjust the flow of information
- "Gates": "removing gate", "input gate", "output gate"
- Step1: process "input sentence" by encoder, creating "feature vector"
- Step2: process "feature vector" by decoder, creating "output sentence"
================================================================================
Weakness of LSTM driven Seq2Seq
- It's lack of capability with only "gates" which adjust the flow of information
- "Gates": "removing gate", "input gate", "output gate"
 - Due to above limitation of gates,
if input sentence becomes longer, LSTM-Seq2Seq becomes confused
================================================================================
Attention
Attention module focuses on important part from the sentence
"Important part" is directly passed to "decoder"
- Due to above limitation of gates,
if input sentence becomes longer, LSTM-Seq2Seq becomes confused
================================================================================
Attention
Attention module focuses on important part from the sentence
"Important part" is directly passed to "decoder"
 ================================================================================
================================================================================
 - When decorder creates output words,
"attention layer" decides what information "decoder" should take
================================================================================
Transformer
- LSTM is not used
- Attention module consisits of "Encoder-Decoder" model
================================================================================
Transformer does "self-attention"
- When decorder creates output words,
"attention layer" decides what information "decoder" should take
================================================================================
Transformer
- LSTM is not used
- Attention module consisits of "Encoder-Decoder" model
================================================================================
Transformer does "self-attention"
 ================================================================================
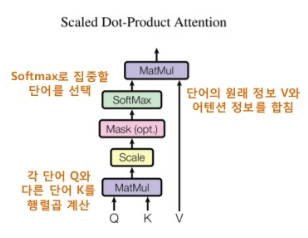
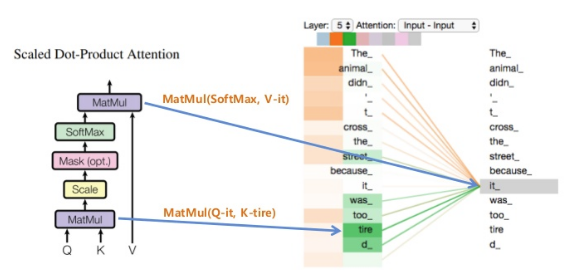
How "transformer" does the "self-attention"?
- Use Scaled Dot-Product Attention module
- Each word is converted into Q,K,V
- Perform: (each word $$$Q$$$) $$$\cdot$$$ (other word $$$K$$$)
- SoftMax: select important word which transformer will pay attention to
- (import word vector after softmaxt) $$$\cdot$$$ (original word information $$$V$$$)
================================================================================
How "transformer" does the "self-attention"?
- Use Scaled Dot-Product Attention module
- Each word is converted into Q,K,V
- Perform: (each word $$$Q$$$) $$$\cdot$$$ (other word $$$K$$$)
- SoftMax: select important word which transformer will pay attention to
- (import word vector after softmaxt) $$$\cdot$$$ (original word information $$$V$$$)
 ================================================================================
================================================================================
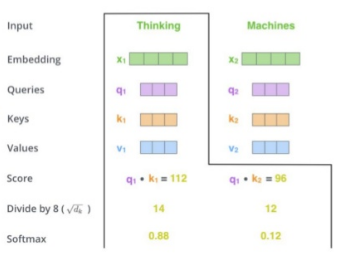 - Illustration of how "Scaled Dot-Product Attention module" works
- Input: 2 words
- Embedding: feature vector from 2 words
- Create Q,K,V vector from 2 feature vectors
- Score: $$$Q \cdot K$$$
- Divide by 8: maybe "Scale module"
- Softmax: 2 softmaxed-numbers from 2 word
It turns out "Thinking" is important word and transformer will pay attention to "Thinking"
================================================================================
- Illustration of how "Scaled Dot-Product Attention module" works
- Input: 2 words
- Embedding: feature vector from 2 words
- Create Q,K,V vector from 2 feature vectors
- Score: $$$Q \cdot K$$$
- Divide by 8: maybe "Scale module"
- Softmax: 2 softmaxed-numbers from 2 word
It turns out "Thinking" is important word and transformer will pay attention to "Thinking"
================================================================================
 ================================================================================
Encoder and Decoder structure in Transformer
- Multiple encoders
================================================================================
Encoder and Decoder structure in Transformer
- Multiple encoders
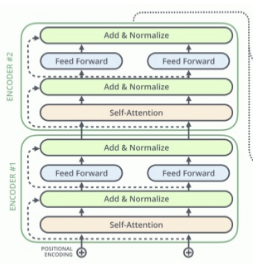 - Multiple decoders
- Multiple decoders
 - Fully connected layer and Softmax layer
- Fully connected layer and Softmax layer
 - Entire view
- Entire view
 ================================================================================
BERT (Bidirectional Encoder Representations from Transformers)
- Deep learning language model which uses pretraining to have general language understanding
- BERT is composed of transformers
================================================================================
Transfer learning (or fine tuning)
================================================================================
BERT (Bidirectional Encoder Representations from Transformers)
- Deep learning language model which uses pretraining to have general language understanding
- BERT is composed of transformers
================================================================================
Transfer learning (or fine tuning)
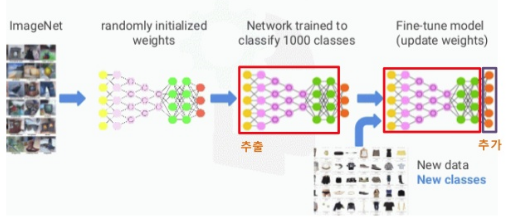 - Dataset: ImageNet
- Randomly initialized weight in the neural network
- Trainable parameters in the network is trained
by using ImageNet dataset which has 100 classes
- Save trained parameter into the file
- Prepare new data which has more classes
- Append new layer which has more output classes
- Load trained parameter and fill the loaded parameter values into network
- Perform training step over new dataset
================================================================================
Tranfer learning NLP models in 2018
- Dataset: ImageNet
- Randomly initialized weight in the neural network
- Trainable parameters in the network is trained
by using ImageNet dataset which has 100 classes
- Save trained parameter into the file
- Prepare new data which has more classes
- Append new layer which has more output classes
- Load trained parameter and fill the loaded parameter values into network
- Perform training step over new dataset
================================================================================
Tranfer learning NLP models in 2018
 ================================================================================
Structure of BERT
- Use only "encoder network" from "transformer"
- BERT Base: 12 number of tranformer blocks
- BERT Large: 24 number of tranformer blocks
================================================================================
Pretrain BERT to give general language understanding to the BERT
Dataset
- BooksCorpus: 800 million of words
- Wikipedia: 2500 million of words
================================================================================
How to pretrain BERT network?
Method1: mask some words
================================================================================
Structure of BERT
- Use only "encoder network" from "transformer"
- BERT Base: 12 number of tranformer blocks
- BERT Large: 24 number of tranformer blocks
================================================================================
Pretrain BERT to give general language understanding to the BERT
Dataset
- BooksCorpus: 800 million of words
- Wikipedia: 2500 million of words
================================================================================
How to pretrain BERT network?
Method1: mask some words
 * Details
- Input sentence with special tokens like CLS, SEP
* Details
- Input sentence with special tokens like CLS, SEP
 - Randomly mask 15% of words of the input sentence
- Randomly mask 15% of words of the input sentence
 - improvisation is replaced with "MASK" token
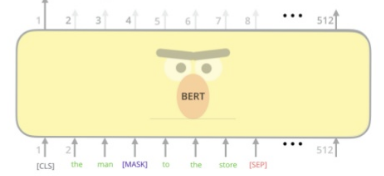
- Max length of input data: 512
- Create output vector (512 dimension) from BERT network
- improvisation is replaced with "MASK" token
- Max length of input data: 512
- Create output vector (512 dimension) from BERT network
 - Pass output vector into FFNN+Softmax layer
to create probability values (2500 million number of probability values)
- Pass output vector into FFNN+Softmax layer
to create probability values (2500 million number of probability values)
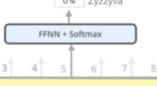 - Following stands for all English words (like 2500 million)
from Aardvark to Zyzzyva
- Following stands for all English words (like 2500 million)
from Aardvark to Zyzzyva
 - masked word has high probability value
and it means BERT model could predict "masked word" correctly,
and it means BERT mdoel could understand general language model
================================================================================
How to pretrain BERT network?
Method2: predict next sentence
- masked word has high probability value
and it means BERT model could predict "masked word" correctly,
and it means BERT mdoel could understand general language model
================================================================================
How to pretrain BERT network?
Method2: predict next sentence
 * Details
- Input data: 2 sentences (sentence A + sentence B)
Input data has CLS (starting position), MASK (masked words), SEP (separation to the 2 sentences) tokens
- Perform tokenization on the input sentence
* Details
- Input data: 2 sentences (sentence A + sentence B)
Input data has CLS (starting position), MASK (masked words), SEP (separation to the 2 sentences) tokens
- Perform tokenization on the input sentence
 - Max length of input sentence is 512
- Use BERT network
- Max length of input sentence is 512
- Use BERT network
 - Get output vector (512 dimension)
- Pass output vector into FFNN+Softmax layer
- Get output vector (512 dimension)
- Pass output vector into FFNN+Softmax layer
 - Given 2 sentence is "continous sentence"?
- Given 2 sentence is "continous sentence"?
 ================================================================================
Embedding input data for BERT
Embedding_for_BERT = token_embedding + segment_embedding + position_embedding
================================================================================
Embedding input data for BERT
Embedding_for_BERT = token_embedding + segment_embedding + position_embedding
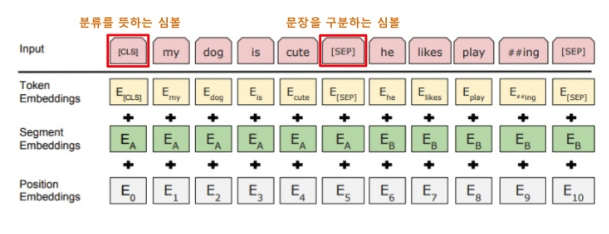 * Details
- Raw input data before "BERT embedding"
* Details
- Raw input data before "BERT embedding"
 - CLS: starting position, or class
- SEP: to separate 2 sentence
- Apply "token embedding" into input data
- CLS: starting position, or class
- SEP: to separate 2 sentence
- Apply "token embedding" into input data
 - Apply "segment embedding"
- Apply "segment embedding"
 - Apply "position embedding"
- Apply "position embedding"
 ================================================================================
Use transfer learning on pretrained BERT network
- Classify 2 sentences
================================================================================
Use transfer learning on pretrained BERT network
- Classify 2 sentences
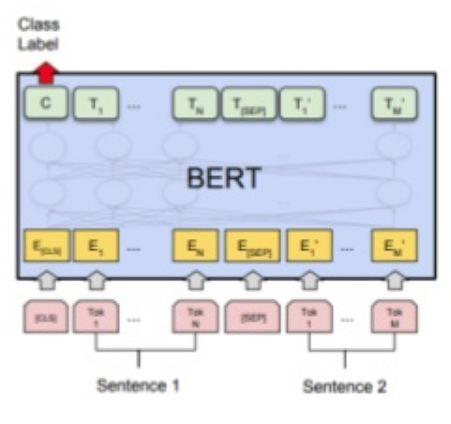 - CLS: token
- Sentence1
- SEP: token
- Sentence2
- Preprocess input data
- Pass input data into BERT network
- Get class from C
================================================================================
- Q and A model
- CLS: token
- Sentence1
- SEP: token
- Sentence2
- Preprocess input data
- Pass input data into BERT network
- Get class from C
================================================================================
- Q and A model
 - CLS: token
- Sentence as question
- SEP: token
- Sentence as answer paragraph
- Preprocess input data
- Pass input data into BERT network
================================================================================
- Classify "one given sentence"
- CLS: token
- Sentence as question
- SEP: token
- Sentence as answer paragraph
- Preprocess input data
- Pass input data into BERT network
================================================================================
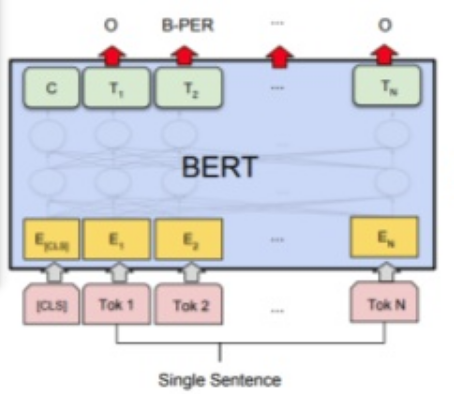
- Classify "one given sentence"
 ================================================================================
- POS tagging on single sentence
================================================================================
- POS tagging on single sentence
 ================================================================================
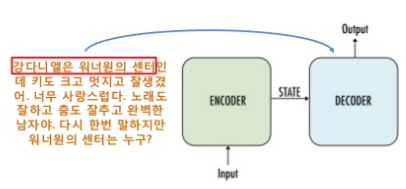
SQuAD: Standford Question Answering Dataset
Given paragraph
================================================================================
SQuAD: Standford Question Answering Dataset
Given paragraph
 Question
Question
 Ground truth answer which BERT should make
Ground truth answer which BERT should make
 ================================================================================
BERT words well than other models
================================================================================
BERT words well than other models
 ================================================================================
================================================================================