http://hero4earth.com/blog/learning/2018/01/17/NLP_Basics_01/
================================================================================
- Sentence example:
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness
- Bag Of Words
BOW={"It":1,"was":2,"the":3,"best":4,"of":5,"times":6,"worst":7,"age":8,"wisdom":9,"foolishness":10}
================================================================================
- Sentence to frequency
- Given sentence: it was the worst of times
frequency={"It":1,"was":1,"the":1,"best":0,"of":1,"times":1,"worst":1,"age":0,"wisdom":0,"foolishness":0}
================================================================================
Count Vectorizer
- Document1: He is a lazy boy. She is also lazy.
- Document2: Neeraj is a lazy person.
- Tokens for doc1 and doc2: ["He","She","lazy","boy","Neeraj","person"]
- Doc1 and doc2 can be modeld into (2,6) 2D array
He She lazy boy Neeraj person
Doc1 1 1 2 1 0 0
Doc2 0 0 1 0 1 1
Entire_document=[[1,1,2,1,0,0],
[0,0,1,0,1,1]]
- Count vectorizer is not efficinet because it creates too massive array
when it represents a text documents
================================================================================
TF-IDF (Term Frequency - Inverse Document Frequency) Vectorizer
document1
Term Count
This 1
is 1
about 2
Messi 4
document2
Term Count
This 1
is 2
about 1
TF-IDF 1
- TF score = $$$\dfrac{\text{frequency_in_specific_document}}{\text{num_of_terms_in_specific_document}}$$$
TF_of_"This"_in_doc1=1/(1+1+2+4)=1/8
TF_of_"This"_in_doc2=1/(1+2+1+1)=1/5
TF_of_"Messi"_in_doc1=4/(1+1+2+4)=4/8
- IDF score = $$$\log{\dfrac{\text{number_of_documents_in_entire_corpus}}{\text{number_of_documents_which_has_specific_term}}}$$$
IDF_of_"This"=log((1+1)/(1+1))=log1=0
IDF_of_"Messi"=log((1+1)/(1+0))=log(2/1)=0.301
- TF-IDF score
TF-IDF_of_"This"_in_doc1=TF*IDF=(1/8)*0=0
TF-IDF_of_"Messi"_in_doc1=TF*IDF=(4/8)*0.301=0.15
- Meaning
Term "Messi" is important in doc1
================================================================================
Above frequent based methods can find some "feature" of word from the text data
But frequent based methods can't find the relationship between words
For example, "Soviet" has strong relationship with "Union"
Soviet can be expressed as vector like soviet=[0.1,-0.5,0.5,0.2]
Union can be expressed as vector like union=[0.2,-0.4,0.5,0.15]
Both has near Euclidean distance
================================================================================
How to crete following dense vectors which can represent each word?
soviet=[0.1,-0.5,0.5,0.2]
union=[0.2,-0.4,0.5,0.15]
- You need to use neural network
================================================================================
Word2Vec
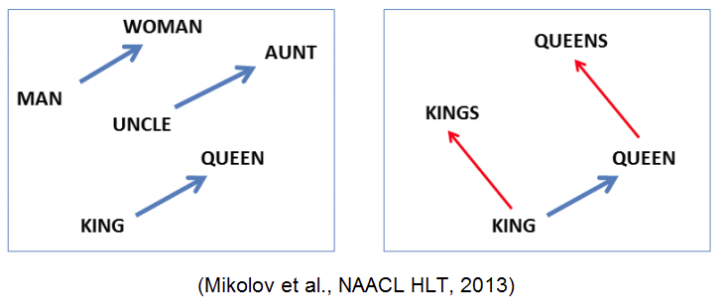 - Each word is repsented by 2D vector in 2D vector space
- Each words have paricular relationship to each other
- Vector operation can be applied to word vectors
================================================================================
Word embedding methods in W2V
- CBOW
- skip-gram (which is more used and which has better performance)
================================================================================
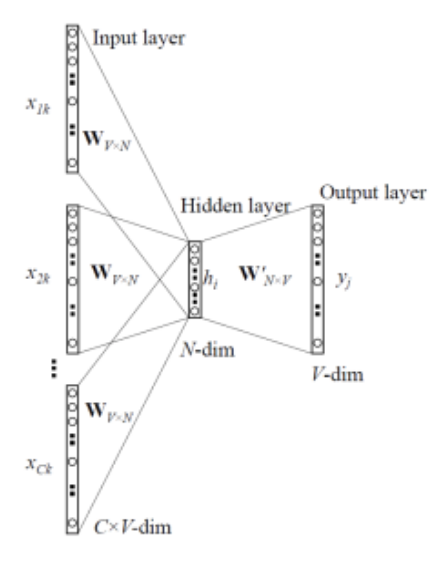
CBOW
- See around-words
- then, predict between-word
- Example: Hot weather needs ___ a drink
- CBOW sees "need", "drink", and CBOW should predict "cold"
- Each word is repsented by 2D vector in 2D vector space
- Each words have paricular relationship to each other
- Vector operation can be applied to word vectors
================================================================================
Word embedding methods in W2V
- CBOW
- skip-gram (which is more used and which has better performance)
================================================================================
CBOW
- See around-words
- then, predict between-word
- Example: Hot weather needs ___ a drink
- CBOW sees "need", "drink", and CBOW should predict "cold"
 - Loss function of CBOW
$$$p(\omega_{O}|\omega_{I})
= \dfrac{\exp{({v^{'}_{\omega_O}}^T \times v_{\omega_I})}}
{\sum\limits_{\omega=1}^{W} \exp{({v^{'}_{\omega_I}}^T \times v_{\omega_I})} }$$$
$$$\omega_O$$$: output word
$$$\omega_I$$$: context words
================================================================================
Skip-gram
- See one-word
- then, predict around-words
- Example: Hot weather ___ cold a ___
- Skip-gram sees "cold", and Skip-gram should predict "needs" and "drink"
- Loss function of CBOW
$$$p(\omega_{O}|\omega_{I})
= \dfrac{\exp{({v^{'}_{\omega_O}}^T \times v_{\omega_I})}}
{\sum\limits_{\omega=1}^{W} \exp{({v^{'}_{\omega_I}}^T \times v_{\omega_I})} }$$$
$$$\omega_O$$$: output word
$$$\omega_I$$$: context words
================================================================================
Skip-gram
- See one-word
- then, predict around-words
- Example: Hot weather ___ cold a ___
- Skip-gram sees "cold", and Skip-gram should predict "needs" and "drink"
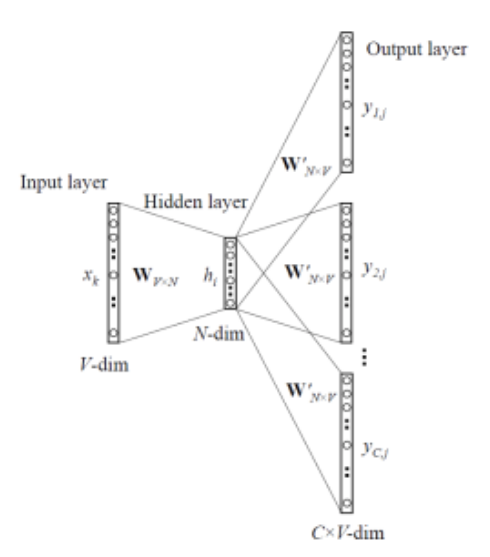 - Advantage of Skip-gram
- It can find multiple-words which are semantically related to "one word"
================================================================================
Seq2Seq model
- Encoder: converts input sentence (input sequence) into vector data
- Decoder: takes vector data and outputs "target data (output sequence)"
- Disadvantage of Seq2Seq
- As input sentence becomes longer and longer, performance becomes degradation
================================================================================
Attention
- It overcomes the weakness of Seq2Seq model
by paying attention to the important parts in the text
- Advantage of Skip-gram
- It can find multiple-words which are semantically related to "one word"
================================================================================
Seq2Seq model
- Encoder: converts input sentence (input sequence) into vector data
- Decoder: takes vector data and outputs "target data (output sequence)"
- Disadvantage of Seq2Seq
- As input sentence becomes longer and longer, performance becomes degradation
================================================================================
Attention
- It overcomes the weakness of Seq2Seq model
by paying attention to the important parts in the text