Lecture note from following lectur.
https://www.youtube.com/watch?v=I7JpGYK3Y-Y&list=PL9mhQYIlKEhdorgRaoASuZfgIQTakIEE9&index=3
================================================================================
Unit of processing in deep learning is vector than symbol
So, you have to perform "symbol to vector" preprocessing for NLP.
You can use various techniques for "symbol to vector"
such as "One-hot representation" and "Distributed representation"
================================================================================
"One-hot representation" and "Distributed representation"
 ================================================================================
"One-hot representation"
Suppose your word dictionary has 1000 words
and it has a word cat in 4th position
To express word "cat", you can create vector like $$$[0,0,0,1,0,...]$$$
Advantage of "One-hot representation":
you can perfectly convert "cat in one hot vector" to "word cat", vice versa.
Disadvange of "One-hot representation":
$$$[0,0,0,1,0,...]$$$ only can represent one word "cat"
But what modern neural network tries to do is
that it tries to consider marginal information around cat,
such as mammals, lions, tigers, etc
Human brain also activates related information like lions, tigers, mammals
when you think of cat, as categorized memories.
================================================================================
"Distributed representation"
All information which is related to cat is distributed into dense vector.
And that one dense vector represents a word cat.
================================================================================
================================================================================
"One-hot representation"
Suppose your word dictionary has 1000 words
and it has a word cat in 4th position
To express word "cat", you can create vector like $$$[0,0,0,1,0,...]$$$
Advantage of "One-hot representation":
you can perfectly convert "cat in one hot vector" to "word cat", vice versa.
Disadvange of "One-hot representation":
$$$[0,0,0,1,0,...]$$$ only can represent one word "cat"
But what modern neural network tries to do is
that it tries to consider marginal information around cat,
such as mammals, lions, tigers, etc
Human brain also activates related information like lions, tigers, mammals
when you think of cat, as categorized memories.
================================================================================
"Distributed representation"
All information which is related to cat is distributed into dense vector.
And that one dense vector represents a word cat.
================================================================================
 How can you convert natural language into meaningful mathematical vector?
For that, you can use:
- Neural Language Modeling
- Word2Vec(Skipgram, CBOW)
- Glove
- Sentence2Vec
- Doc2Vec
- etc
================================================================================
Standard method for converting natural language into meaningful vector is Word2Vec
Idea of Word2Vec is as follow
Suppose a sentence "Tom eats apple"
Word2Vec supposes information which represents "eats" is contained in "Tom" and "apple"
as well as "eats" itself.
You can train neural network using above assumption.
--------------------------------------------------------------------------------
Then, it means you can predict one word like "eats"
when "Tom" and "apple" are given in training step
How can you convert natural language into meaningful mathematical vector?
For that, you can use:
- Neural Language Modeling
- Word2Vec(Skipgram, CBOW)
- Glove
- Sentence2Vec
- Doc2Vec
- etc
================================================================================
Standard method for converting natural language into meaningful vector is Word2Vec
Idea of Word2Vec is as follow
Suppose a sentence "Tom eats apple"
Word2Vec supposes information which represents "eats" is contained in "Tom" and "apple"
as well as "eats" itself.
You can train neural network using above assumption.
--------------------------------------------------------------------------------
Then, it means you can predict one word like "eats"
when "Tom" and "apple" are given in training step
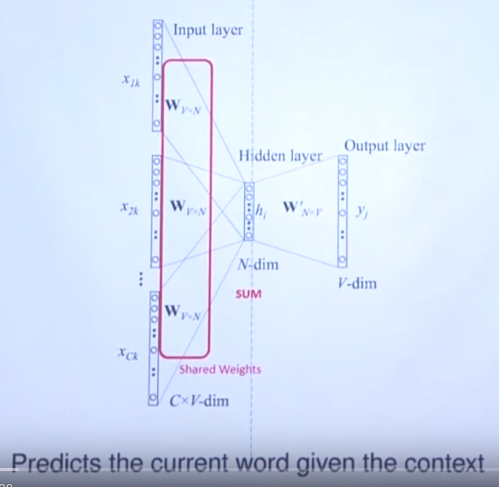 This is continuous bag-of-words architecture
--------------------------------------------------------------------------------
Also you can predict multiple surrounding words like "Tom" and "apple"
when "eats" is given in the training step.
This is continuous bag-of-words architecture
--------------------------------------------------------------------------------
Also you can predict multiple surrounding words like "Tom" and "apple"
when "eats" is given in the training step.
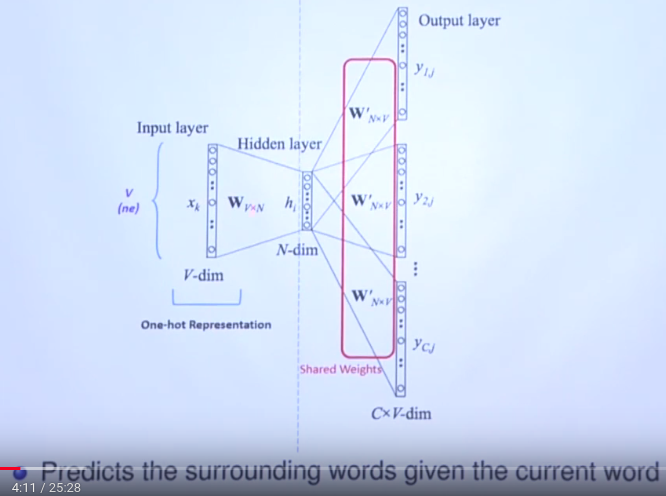 This is skip-gram architecture
--------------------------------------------------------------------------------
Importantly note that you can see one dense vector in hidden layer in both cases.
And that dense vector is created in the process of mapping from input word to output words
And that dense vector represents vector which explains "input word"
================================================================================
When you proceed above training, with getting dense vectors which represent words,
there occured interesting discovery.
1. Vector can be performed arithmetic operation
2. If you perform following operation,
King vector - Man vector + Woman vector = output vector
output vector is mapped to place where Queen vector is supposed to be.
================================================================================
Token Embedding
This is skip-gram architecture
--------------------------------------------------------------------------------
Importantly note that you can see one dense vector in hidden layer in both cases.
And that dense vector is created in the process of mapping from input word to output words
And that dense vector represents vector which explains "input word"
================================================================================
When you proceed above training, with getting dense vectors which represent words,
there occured interesting discovery.
1. Vector can be performed arithmetic operation
2. If you perform following operation,
King vector - Man vector + Woman vector = output vector
output vector is mapped to place where Queen vector is supposed to be.
================================================================================
Token Embedding
 1. Token can be "word", "character", "morpheme", "phrase", etc
2. Suppose "apple" as "word token"
3. Find index of word apple in your dictionary which has 10000 words.
Suppose it's located in 3rd postion.
4. Create one hot representation which is 10000 dimenstion vector
$$$[0,0,1,0,0,...]$$$
5. Use embedding layer (from PyTorch or TensorFlow)
which converts "one hot representation" to "dense vector"
================================================================================
Translation problem can have 500 to 600 dimenstion vector to encode one token
But generally, you need 50 to 200 dimensional vector to encode one token
================================================================================
Embedding lookup is implemented by using matrix multiplication
1. Token can be "word", "character", "morpheme", "phrase", etc
2. Suppose "apple" as "word token"
3. Find index of word apple in your dictionary which has 10000 words.
Suppose it's located in 3rd postion.
4. Create one hot representation which is 10000 dimenstion vector
$$$[0,0,1,0,0,...]$$$
5. Use embedding layer (from PyTorch or TensorFlow)
which converts "one hot representation" to "dense vector"
================================================================================
Translation problem can have 500 to 600 dimenstion vector to encode one token
But generally, you need 50 to 200 dimensional vector to encode one token
================================================================================
Embedding lookup is implemented by using matrix multiplication
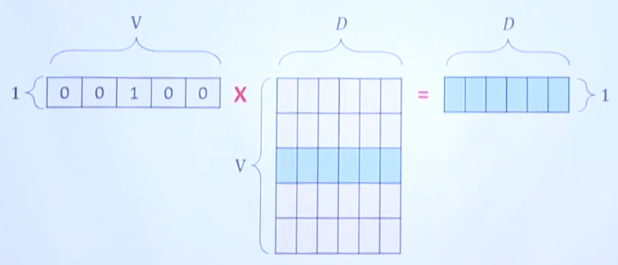 (1,V): one hot representation for one token
(V,D) matrix: embedding matrix
which is initialized randomly at initial time
And element of that matrix is filled with optimized values via training step
to make best right dense vector
(1,D): best dense vector which represents input one hot representation
================================================================================
(1,V): one hot representation for one token
(V,D) matrix: embedding matrix
which is initialized randomly at initial time
And element of that matrix is filled with optimized values via training step
to make best right dense vector
(1,D): best dense vector which represents input one hot representation
================================================================================
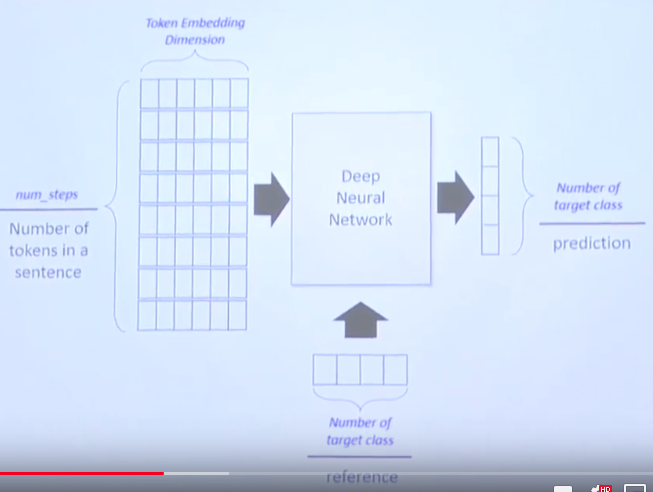 - Number of steps: length of sentence
In this example, you use token as character.
T
o
m
g
o
e
s
t
o
s
c
h
o
o
l
- Token Embeeding Dimension: if you choose you would use 50 dimension,
Token Embeeding Dimension just becomes 50 dimension
- Class is 4 (positive, negative, neutral, objective) in this example
================================================================================
Many packages like PyTorch, TensorFlow abstract "embeding layer"
- Number of steps: length of sentence
In this example, you use token as character.
T
o
m
g
o
e
s
t
o
s
c
h
o
o
l
- Token Embeeding Dimension: if you choose you would use 50 dimension,
Token Embeeding Dimension just becomes 50 dimension
- Class is 4 (positive, negative, neutral, objective) in this example
================================================================================
Many packages like PyTorch, TensorFlow abstract "embeding layer"
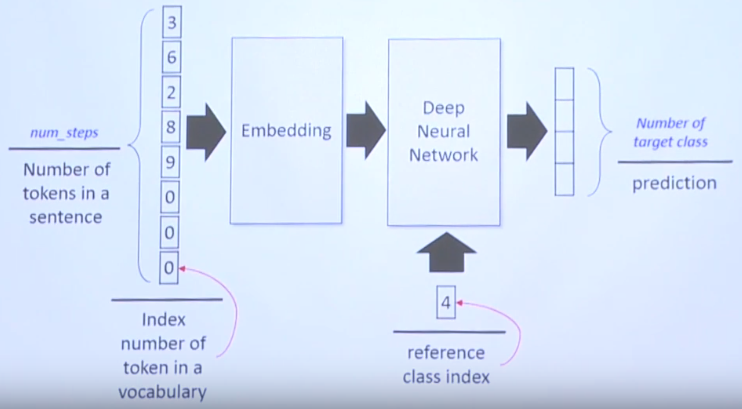 - 3 means index for Tom from your dictionary
6 means index for "goes" from your dictionary
0 means padding
...
- 4 in class index means target class index like objective
================================================================================
Neural Network design
- 3 means index for Tom from your dictionary
6 means index for "goes" from your dictionary
0 means padding
...
- 4 in class index means target class index like objective
================================================================================
Neural Network design
 - X: vector which is composed of indices of tokens
- Embedding Lookup: is trainable which converts input vector into dense vector
- Dropout layer
- RNN layer
- Fully connected layer which outputs 4 values which represent one predicted class
- Loss function
================================================================================
- X: vector which is composed of indices of tokens
- Embedding Lookup: is trainable which converts input vector into dense vector
- Dropout layer
- RNN layer
- Fully connected layer which outputs 4 values which represent one predicted class
- Loss function
================================================================================