https://www.youtube.com/watch?v=P6Dm-c1pb90
================================================================================
Topic modeling (document modeling, topic mining):
With respect to the topic of the document,
extract set of keywords which are related to topic
================================================================================
ML algorithm should get topics in unsupervised manner
 ================================================================================
Each topic should be related to keywords in the document
================================================================================
Each topic should be related to keywords in the document
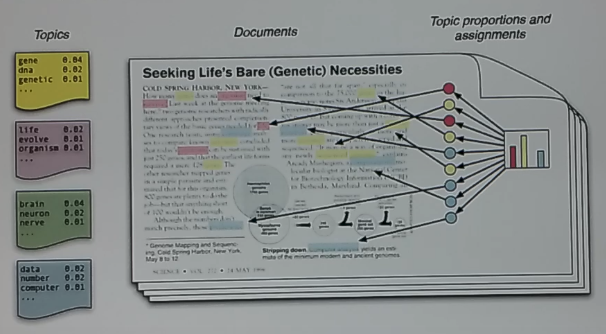 ================================================================================
Pipeline of topic modeling
- Collect data by using web crawling
- Output: document data
- Preprocess data
- Remove HTML markups
- Useless characters
- Get useful data
- Data analysis
- Find "topics" from document
- Find keywords (or annoations) which are related to "found topic"
- LDA (latent dirichlet allocation which is based on Bayesian)/ATM/DTM/Nubbi/S-EGTM algorithms
- Output: set of topics and set of keywords
- Predict topic
- Analyze "keywords (or annotations)"
- Predict "future" based on analyzed keywords
- Bayesian graph (when keywords are given, probability of specific prediction ocurring)
================================================================================
================================================================================
Pipeline of topic modeling
- Collect data by using web crawling
- Output: document data
- Preprocess data
- Remove HTML markups
- Useless characters
- Get useful data
- Data analysis
- Find "topics" from document
- Find keywords (or annoations) which are related to "found topic"
- LDA (latent dirichlet allocation which is based on Bayesian)/ATM/DTM/Nubbi/S-EGTM algorithms
- Output: set of topics and set of keywords
- Predict topic
- Analyze "keywords (or annotations)"
- Predict "future" based on analyzed keywords
- Bayesian graph (when keywords are given, probability of specific prediction ocurring)
================================================================================