https://www.youtube.com/watch?v=F4sIkIlGG78
================================================================================
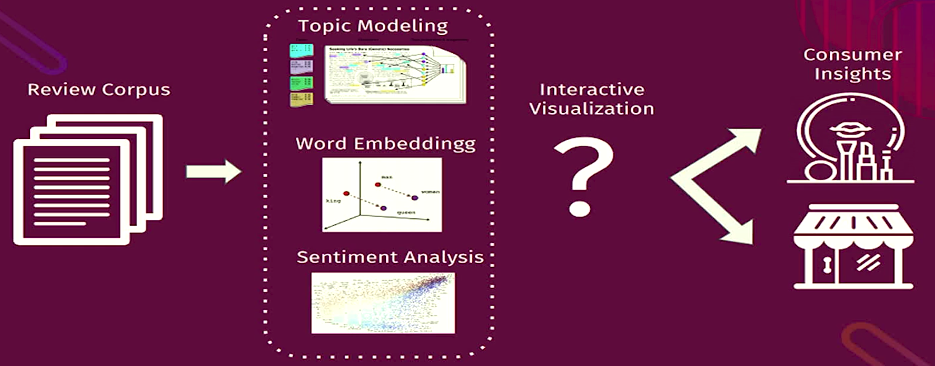 - Review the corpus data based on several options
- Review the corpus data based on several options
 - Perform topic modeling by using LDA
- Perform topic modeling by using LDA
 - Visualize topic modeling
- Visualize topic modeling
 Left: 1 to 5 topics
Right: keywords in each topic
Left: 1 to 5 topics
Right: keywords in each topic
 Based on keywords in topic2,
you can guess topic2 is related to skin-trouble
- Perform word embedding
* Meaning of word (or conceptt) is determined by around-words
Based on keywords in topic2,
you can guess topic2 is related to skin-trouble
- Perform word embedding
* Meaning of word (or conceptt) is determined by around-words
 * Words of Moon, Trump, Jinping are determined as president thing
because there is predident as around-word
* Python is kind of programming language
because there are programming words around Python
* Words of Moon, Trump, Jinping are determined as president thing
because there is predident as around-word
* Python is kind of programming language
because there are programming words around Python
 - Perform sentiment analysis
- Perform sentiment analysis
 * Scaled f-score: which keywords are related to "positive"?
which keywords are related to "negative"?
* Scaled f-score: which keywords are related to "positive"?
which keywords are related to "negative"?
 * Use scattertext
* Use scattertext
 * Keywords which has "positive" sentiment
* Keywords which has "positive" sentiment
 * Keywords which has "negative" sentiment
* Keywords which has "negative" sentiment
 - perform interactive visualization by using pyLDAvis
- Get consumer insights
================================================================================
Word embedding
- perform interactive visualization by using pyLDAvis
- Get consumer insights
================================================================================
Word embedding
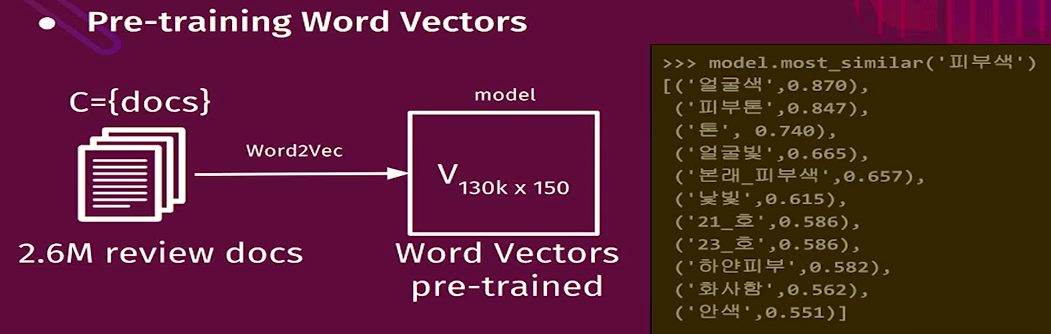 - Create corpus by using 2.6M reviews
- Corpus = {docs}
- Create corpus by using 2.6M reviews
- Corpus = {docs}
 - Use Word2Vec
- Use Word2Vec
 - Get word embeding
- Get word embeding
 - Test
- Test
 - Draw chart by using PCA
- Draw chart by using PCA
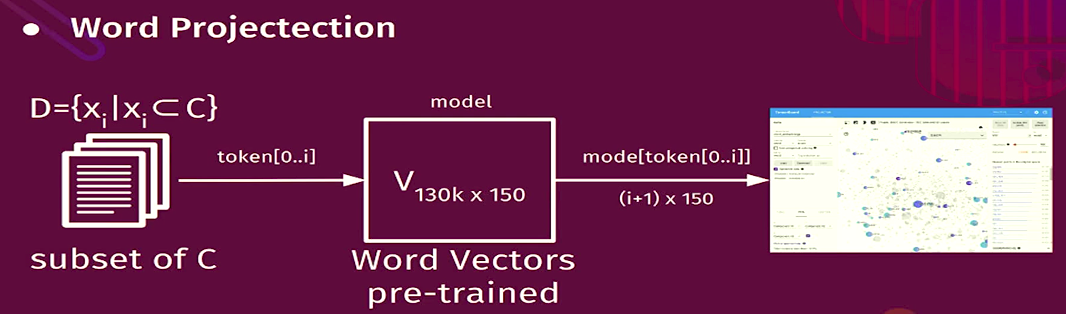 - Use Tensorboard's Projector
- Use Tensorboard's Projector
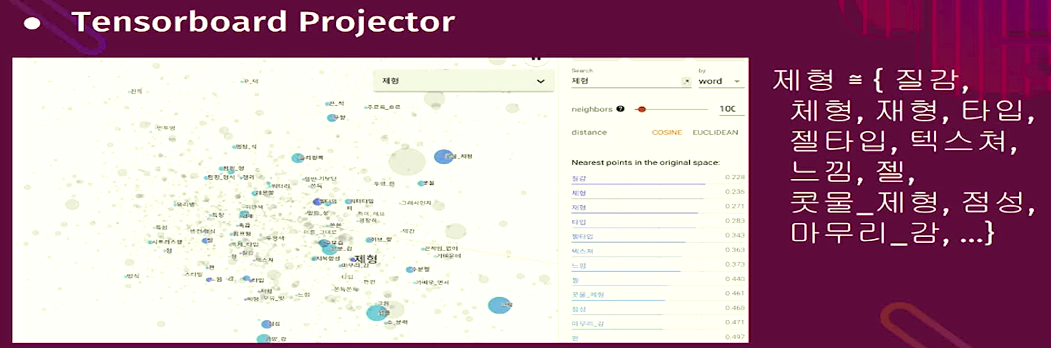 * keyword_you_input={related_keywords}
================================================================================
Future works
* keyword_you_input={related_keywords}
================================================================================
Future works

 ================================================================================
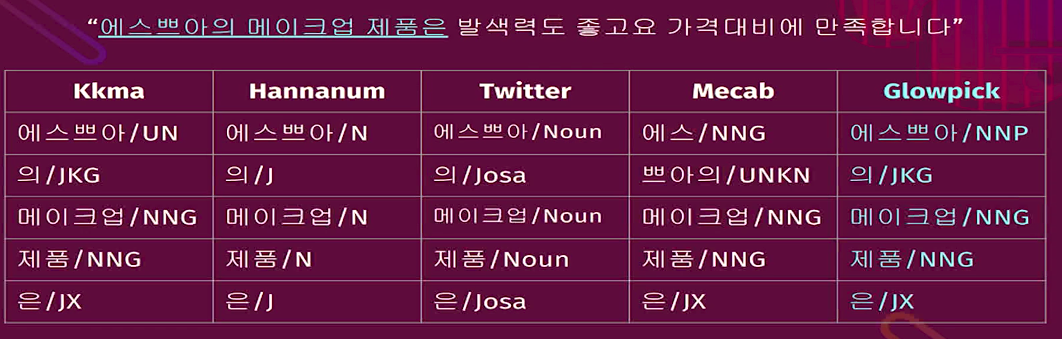
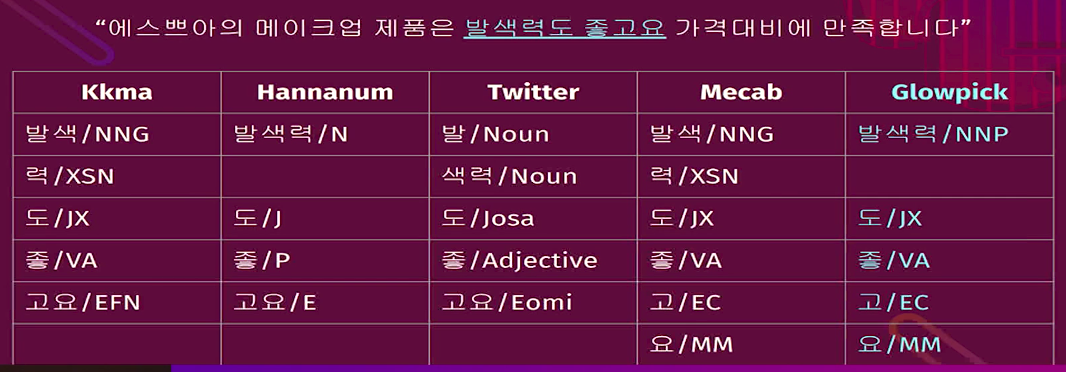
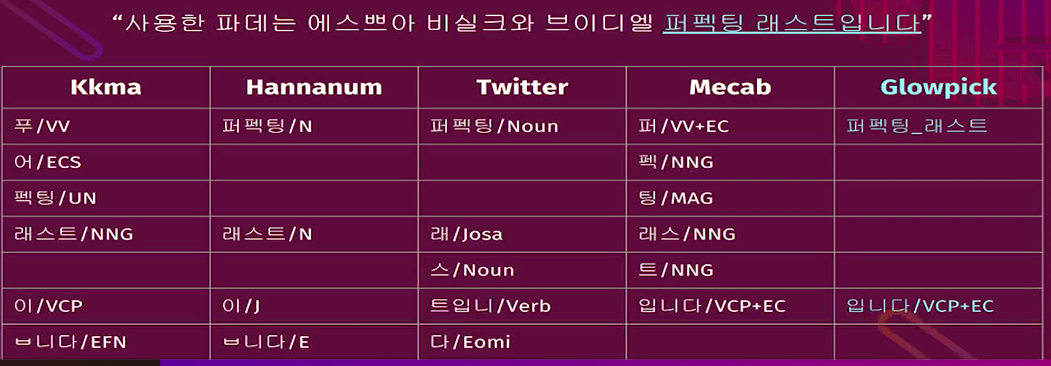
* Feature engineering
Words (corpus) are too domain specific,
so you should replace old "corpus analyzer" with new updated one
================================================================================
Example
================================================================================
* Feature engineering
Words (corpus) are too domain specific,
so you should replace old "corpus analyzer" with new updated one
================================================================================
Example