Key points
MCTS
Policy network
Value network
================================================================================
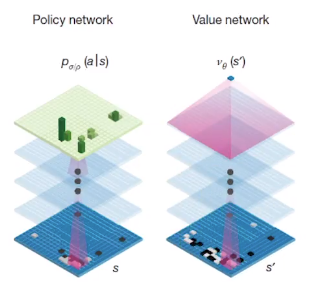 Policy network (or policy, policy function) is used to reduce width of MCTS
It has vertical sticks which represent probabilities to each states.
Length of summation of all vertical sticks should be 1
Value network is used to reduce depth of MCTS
================================================================================
Policy network
Input: state s, for example, 100 states if you have (10,10) grid cells
$$$p_{\sigma/\rho}(a|s)$$$: probability distribution of action
Meaning: you are in state s.
policy network gives you the information (as in probability distribution form) to which you should go
1 cell: 30% probability good
2 cell: 10% probability good
...
$$$\sum\limits_{\text{all probabilities wrt all states}}=1$$$
================================================================================
If MCTS is perfect, you only need MCTS.
But practically, MCTS can't be perfect and MCTS can take too much time to search possible cases.
So, MCTS is helped by policy network and value network
to reduce width and depth in search algorithm
================================================================================
Also you should note that
if you use policy network and value network in reinforcement learning,
it's already working good as generalization solution method.
But if you use policy network and value network along with MCTS
(which performs game simulation up to the end of game), that framework becomes more powerful.
================================================================================
Value network
Input: state s
Output: probability of you winning (in other words, value of current state)
How can value network be useful?
If you use value network, you perform "action",
then, value network let you know whether you will win or lose.
Then, you can stop MCTS at that point cause your winning rate is proved.
================================================================================
Policy network (or policy, policy function) is used to reduce width of MCTS
It has vertical sticks which represent probabilities to each states.
Length of summation of all vertical sticks should be 1
Value network is used to reduce depth of MCTS
================================================================================
Policy network
Input: state s, for example, 100 states if you have (10,10) grid cells
$$$p_{\sigma/\rho}(a|s)$$$: probability distribution of action
Meaning: you are in state s.
policy network gives you the information (as in probability distribution form) to which you should go
1 cell: 30% probability good
2 cell: 10% probability good
...
$$$\sum\limits_{\text{all probabilities wrt all states}}=1$$$
================================================================================
If MCTS is perfect, you only need MCTS.
But practically, MCTS can't be perfect and MCTS can take too much time to search possible cases.
So, MCTS is helped by policy network and value network
to reduce width and depth in search algorithm
================================================================================
Also you should note that
if you use policy network and value network in reinforcement learning,
it's already working good as generalization solution method.
But if you use policy network and value network along with MCTS
(which performs game simulation up to the end of game), that framework becomes more powerful.
================================================================================
Value network
Input: state s
Output: probability of you winning (in other words, value of current state)
How can value network be useful?
If you use value network, you perform "action",
then, value network let you know whether you will win or lose.
Then, you can stop MCTS at that point cause your winning rate is proved.
================================================================================
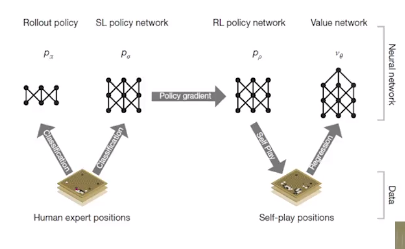 4 prerequisites to use MCTS
1. Rollout policy
2. SL (supervised learning) policy network
3. RL policy network
4. Value network
3 things are needed to create policy and 1 thing is needed to create value
================================================================================
SL policy: policy which is trained via supervised learning method
- In SL policy, you train neural network
- Neural network is a function which has high degree of freedom
so that which can approximate any functions
- Dataset: 30000000 number of professional Go players' match records
- Input: grid floor of Go match,
for example, imagine there are stones at location of 1,2,3 points
- Output: location where you should put the stone
for example, when stones are put at 1,2,3 points,
professional Go player put the stone at 5 point (which is label)
- Upper bound: professional Go player level
- Network structure:
(1) 13 layers
(2) CNN
(3) Classification problem (class $$$361=19\times 19$$$)
(4) proven accuracy: 57% which means trainned network can output predicted true label
in 57% probability
(5) 50 GPUs are used for 3 weeks
(6) 330000000 number of updating network
================================================================================
Rollout policy
- Everything is same with SL policy except for several things.
- SL policy is heavy. When you throw a state, output comes in long time
(but actually 3 miliseconds for one prediction)
- Rollout policy is small policy (but accuracy is rather less)
It takes 2 microseconds for one prediction.
- 1 microsecond $$$\times$$$ 1000 = 1 millisecond
- Why you should use small Rollout policy?
This project is important with much simulation.
Even if there is tradeoff to accuracy, fast and more simulation are advantages of rollout policy.
- structure
(1) one layer: FC+softmax
(2) feature of rollout has many features
which domain experts generate like heuristic method
For a reference, feature of SL: (19,19,48)
(3) accuracy: 24%
================================================================================
RL (reinforcement learning) policy network
RL policy is reinforced policy from SL
- Method: self play
- Definition of reinforcement learning:
(1) You perform tons of "trial and error"
(2) Find good decision from (1)
by increasing probability of "win-proven decision"
and by decreasing probability of "lose-proven decision"
- What's different between MCTS and RL
(1) Common: they use simulation
(2) RL uses REINFORCE algorithm
- After training network via RL network,
if SL and RL have a match, RL wins in 80% of probability
- Training: 50 GPUs for 1 day
- Network structure and traing method:
(1) Same network with SL
(2) By using RL method (competing each other), update trainable parameters of 2 networks
================================================================================
Value network
- Structure
(1) Neural network
(2) Number of class in last layer: 1 (win or lose)
(3) Regression
- Mission:
(1) value network predicts who will win
with assuming that game is played up to the end using RL policy
- Value network uses RL policy
- Training information
(1) Train network over 30000000 states
(2) 30000000 states were different
(3) For example, there are multiple states like 200 states in "one game"
(4) But developers throw away 199 states and use 1 states from one game as 1 state for train dataset
(5) And they create 30000000 states in this manner
================================================================================
4 prerequisites to use MCTS
1. Rollout policy
2. SL (supervised learning) policy network
3. RL policy network
4. Value network
3 things are needed to create policy and 1 thing is needed to create value
================================================================================
SL policy: policy which is trained via supervised learning method
- In SL policy, you train neural network
- Neural network is a function which has high degree of freedom
so that which can approximate any functions
- Dataset: 30000000 number of professional Go players' match records
- Input: grid floor of Go match,
for example, imagine there are stones at location of 1,2,3 points
- Output: location where you should put the stone
for example, when stones are put at 1,2,3 points,
professional Go player put the stone at 5 point (which is label)
- Upper bound: professional Go player level
- Network structure:
(1) 13 layers
(2) CNN
(3) Classification problem (class $$$361=19\times 19$$$)
(4) proven accuracy: 57% which means trainned network can output predicted true label
in 57% probability
(5) 50 GPUs are used for 3 weeks
(6) 330000000 number of updating network
================================================================================
Rollout policy
- Everything is same with SL policy except for several things.
- SL policy is heavy. When you throw a state, output comes in long time
(but actually 3 miliseconds for one prediction)
- Rollout policy is small policy (but accuracy is rather less)
It takes 2 microseconds for one prediction.
- 1 microsecond $$$\times$$$ 1000 = 1 millisecond
- Why you should use small Rollout policy?
This project is important with much simulation.
Even if there is tradeoff to accuracy, fast and more simulation are advantages of rollout policy.
- structure
(1) one layer: FC+softmax
(2) feature of rollout has many features
which domain experts generate like heuristic method
For a reference, feature of SL: (19,19,48)
(3) accuracy: 24%
================================================================================
RL (reinforcement learning) policy network
RL policy is reinforced policy from SL
- Method: self play
- Definition of reinforcement learning:
(1) You perform tons of "trial and error"
(2) Find good decision from (1)
by increasing probability of "win-proven decision"
and by decreasing probability of "lose-proven decision"
- What's different between MCTS and RL
(1) Common: they use simulation
(2) RL uses REINFORCE algorithm
- After training network via RL network,
if SL and RL have a match, RL wins in 80% of probability
- Training: 50 GPUs for 1 day
- Network structure and traing method:
(1) Same network with SL
(2) By using RL method (competing each other), update trainable parameters of 2 networks
================================================================================
Value network
- Structure
(1) Neural network
(2) Number of class in last layer: 1 (win or lose)
(3) Regression
- Mission:
(1) value network predicts who will win
with assuming that game is played up to the end using RL policy
- Value network uses RL policy
- Training information
(1) Train network over 30000000 states
(2) 30000000 states were different
(3) For example, there are multiple states like 200 states in "one game"
(4) But developers throw away 199 states and use 1 states from one game as 1 state for train dataset
(5) And they create 30000000 states in this manner
================================================================================
 ================================================================================
================================================================================