This is notes which I wrote as I was taking a video lecture which is originated from
https://www.youtube.com/watch?v=xgoO54qN4lY&list=PLlMkM4tgfjnKsCWav-Z2F-MMFRx-2gMGG&index=2
================================================================================
You suppose there are "environment" and "actor"
Determining "action" is performed by algorithm which you should create
================================================================================
Manually creating all "environment" for every project is arduous and complicated job
OpenAI GYM provides built-in "environments"
Then, task which you only should do is to implement algorithm part
================================================================================
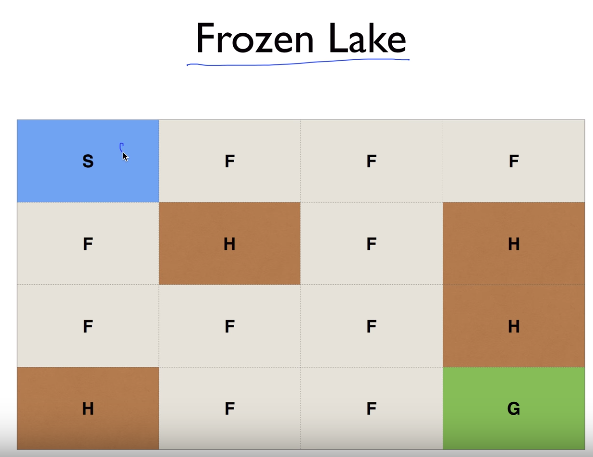 S: starting place
Agent on state S can move "right", "bottom"
F: Frozon place
H: Hole place, agent falls into the hole
G: Goal place
================================================================================
S: starting place
Agent on state S can move "right", "bottom"
F: Frozon place
H: Hole place, agent falls into the hole
G: Goal place
================================================================================
 - There are 4 actions.
- If agent does "action", environment gives "state" and "reward" to the "agent"
- "State" can be represented in various ways.
- Just say S is state 0, right F is 1, right F is 2, right F is 3
0,1,2,3,... can be said as states
- If "agent" arrives to "G", "agent" gets reward 1
================================================================================
- There are 4 actions.
- If agent does "action", environment gives "state" and "reward" to the "agent"
- "State" can be represented in various ways.
- Just say S is state 0, right F is 1, right F is 2, right F is 3
0,1,2,3,... can be said as states
- If "agent" arrives to "G", "agent" gets reward 1
================================================================================
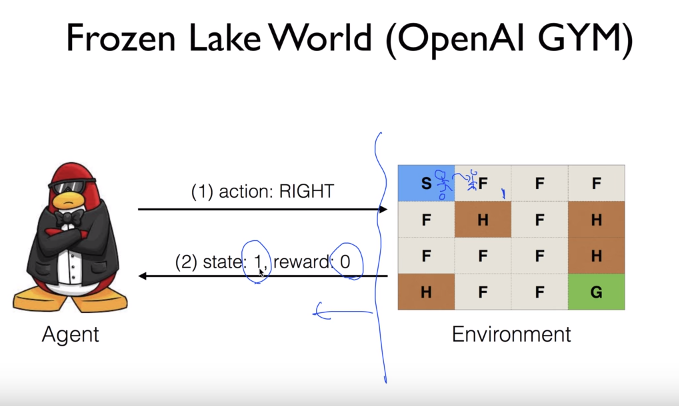 Suppose agent does "RIGHT" action.
Then, agent is given "state 1" and "reward 0"
================================================================================
Suppose agent does "RIGHT" action.
Then, agent is given "state 1" and "reward 0"
================================================================================
 For human who can see the right paths, above problem is easy.
================================================================================
For human who can see the right paths, above problem is easy.
================================================================================
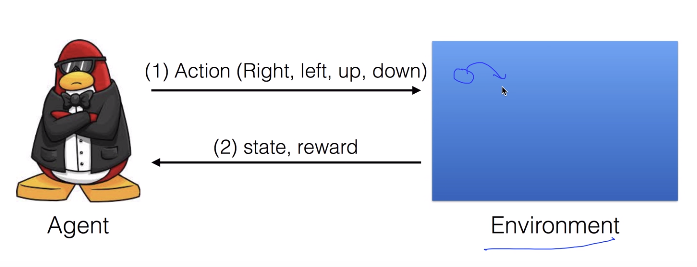
 But you should see the problem like this.
Agent can't see how environment is composed
Consider your life.
You can't fully predict what will happen after you do an action.
You do action, you get feedback like states and rewards
================================================================================
But you should see the problem like this.
Agent can't see how environment is composed
Consider your life.
You can't fully predict what will happen after you do an action.
You do action, you get feedback like states and rewards
================================================================================
 Agent moves, and agent can know that place is frozen place or hole
Agent moves, and agent can know that place is frozen place or hole