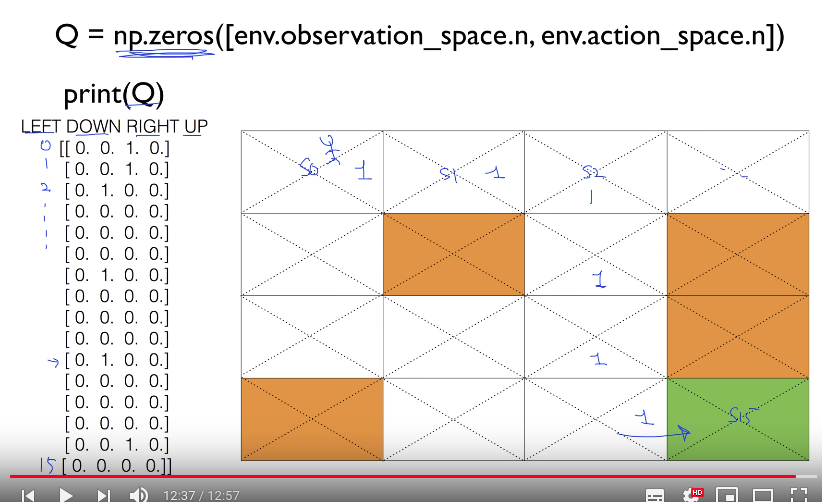
# ================================================================================ import gym import numpy as np import matplotlib.pyplot as plt from gym.envs.registration import register import random as pr # ================================================================================ # Random argmax def rargmax(vector): m=np.amax(vector) indices=np.nonzero(vector==m)[0] returnpr.choice(indices) # ================================================================================ register( id='FrozenLake-v3', entry_point='gym.envs.toy_text:FrozenLakeEnv', kwargs={'map_name':'4x4','is_slippery': False} ) env=gym.make('FrozenLake-v3') # ================================================================================ # c Q: (16,4) 2D array Q=np.zeros([env.observation_space.n,env.action_space.n]) # @ 2000 episodes num_episodes=2000 # ================================================================================ # rList will save results("total rewards" and "steps") per episode rList=[] for i in range(num_episodes): # c state: reset env and get current 1st state state=env.reset() rAll=0 # done=True: end of game done=False # The Q-Table learning algorithm while not done: # c action: select action # Select maximal Q # If Q values have same value, select Q randomly # rargmax(): random argmax() action=rargmax(Q[state,:]) # ================================================================================ # Execute action new_state,reward,done,_=env.step(action) # ================================================================================ # Update Q function Q[state, action] by using equation # : from Q[new_state,:] means all kinds of actions like LRUD Q[state,action]=reward+np.max(Q[new_state,:]) # ================================================================================ # You sum all rewards from each step rAll+=reward # https://raw.githubusercontent.com/youngminpark2559/pracrl/master/shkim-rl/pic/2019_04_22_00:04:43.png # In one episode, agent falls into hole (0) # In second episode, agent goes to terminating place (+1) # rAll stroes 0, +1, -1, etc # ================================================================================ state=new_state rList.append(rAll) # ================================================================================ print("Success rate: "+str(sum(rList)/num_episodes)) print("Final Q-Table Values") print("LEFT DOWN RIGHT UP") print(Q) plt.bar(range(len(rList)),rList,color="blue") plt.show()