# https://www.youtube.com/watch?v=MQ-3QScrFSI&list=PLlMkM4tgfjnKsCWav-Z2F-MMFRx-2gMGG&index=6
================================================================================
The essence of Q learning is updating current Q funcion by using following fomular
$$$\hat{Q}(s,a)\leftarrow r+max_{a'}\hat{Q}(s',a')$$$
- r: reward
- $$$max_{a'}\hat{Q}(s',a')$$$: highest Q value at next state s'
================================================================================
Exploit (use found good path) vs Exploration (try new path)
================================================================================
After learning Q function, agent will always go along the found good path
But agent needs to try "new paths (like down at first place)"
 ================================================================================
================================================================================
 At first, all restaurants have 0 Q values
If you go always randomly, taste is not good.
If you go always to what you know, you can't know new taste.
================================================================================
At first, all restaurants have 0 Q values
If you go always randomly, taste is not good.
If you go always to what you know, you can't know new taste.
================================================================================
 - Suppose there are your scores for each restaurant
- So, you can use this algorithm
Weekdays: exploit
Weekend: exploration
================================================================================
Exploit vs Exploration algorithm
1. "e-greedy"
# c e: small value
e=0.1
# c rand: random value
if rand<e:
# you randomly choose action
a=random
else:
# you use good Q values
a=argmax(Q(s,a))
e=0.1 means 10% exploration, 90% exploit
================================================================================
Exploit vs Exploration algorithm
2. Decaying "e-greedy"
- More exploration at initial training
- Less exploration at late training
for i in range(1000):
e=0.1/(i+1)
# e=0.1 -> 0.01 -> 0.0001 -> ...
# Less exploration as training goes
# Exploration
if random(1)<e:
a=random
# Exploit
else:
a=argmax(Q(s,a))
================================================================================
Exploit vs Exploration algorithm
3. Add random noise
- Suppose you have your scores to the restaurants
- Suppose there are your scores for each restaurant
- So, you can use this algorithm
Weekdays: exploit
Weekend: exploration
================================================================================
Exploit vs Exploration algorithm
1. "e-greedy"
# c e: small value
e=0.1
# c rand: random value
if rand<e:
# you randomly choose action
a=random
else:
# you use good Q values
a=argmax(Q(s,a))
e=0.1 means 10% exploration, 90% exploit
================================================================================
Exploit vs Exploration algorithm
2. Decaying "e-greedy"
- More exploration at initial training
- Less exploration at late training
for i in range(1000):
e=0.1/(i+1)
# e=0.1 -> 0.01 -> 0.0001 -> ...
# Less exploration as training goes
# Exploration
if random(1)<e:
a=random
# Exploit
else:
a=argmax(Q(s,a))
================================================================================
Exploit vs Exploration algorithm
3. Add random noise
- Suppose you have your scores to the restaurants
 - You add random value to the Q values
a=argmax(Q(s,a)+random_values)
# c [0.5,0.6,0.3,0.2,0.5]: Q values
# c [0.2,0.2,0.1,0.9,0.8]: random values
a=argmax([0.5,0.6,0.3,0.2,0.5],[0.2,0.2,0.1,0.9,0.8])
================================================================================
Exploit vs Exploration algorithm
4. Decaying "add random noise"
for i in range(1000):
a=argmax(Q(s,a)+random_values/(i+1))
================================================================================
- You add random value to the Q values
a=argmax(Q(s,a)+random_values)
# c [0.5,0.6,0.3,0.2,0.5]: Q values
# c [0.2,0.2,0.1,0.9,0.8]: random values
a=argmax([0.5,0.6,0.3,0.2,0.5],[0.2,0.2,0.1,0.9,0.8])
================================================================================
Exploit vs Exploration algorithm
4. Decaying "add random noise"
for i in range(1000):
a=argmax(Q(s,a)+random_values/(i+1))
================================================================================
 This is path1
================================================================================
This is path1
================================================================================
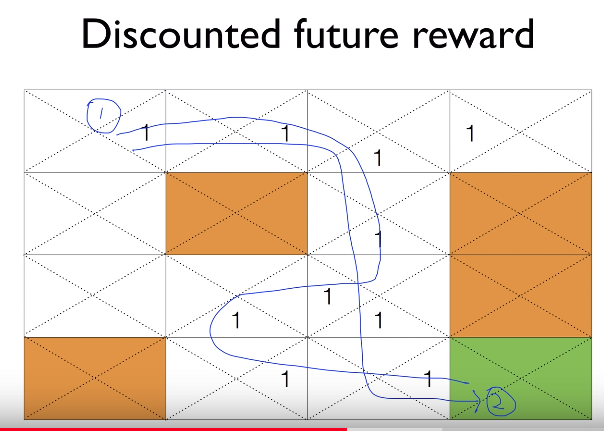 This is path2
================================================================================
Path2 is better
================================================================================
This is path2
================================================================================
Path2 is better
================================================================================
 But when agent is being there, agent is confused because there are 2 ones
This confusing can be resolved by "discounted reward"
================================================================================
"Discounted reward": discount reward which can be obtained in too far future
================================================================================
$$$\hat{Q}(s,a) \leftarrow r + \max_{a^{'}} \hat{Q}(s^{'},a^{'})$$$
r: reward after agent does "action a"
$$$\hat{Q}(s^{'},a^{'})$$$: Q value in future time
================================================================================
Let's discount future value by multiplying 0.9
$$$\hat{Q}(s,a) \leftarrow r + 0.9 \times \max_{a^{'}} \hat{Q}(s^{'},a^{'})$$$
================================================================================
$$$R=r_{1}+...+r_{n}$$$
$$$R_{t}=r_{t}+r_{t+1}+...+r_{n}$$$
$$$R$$$: sum of all rewards
$$$R_{t}$$$: sum of all rewards at time t
================================================================================
Discounted rewards
$$$R_{t}=r_{t}+\gamma r_{t+1}+\gamma^{2}r_{t+2}+...+\gamma^{n-t}r_{n}$$$
$$$r_{t}$$$: current reward (better than future reward )
$$$R_{t}=r_{t}+\gamma (r_{t+1}+\gamma(r_{t+2}+...))$$$
$$$R_{t}=r_{t}+\gamma R_{t+1}$$$
$$$\gamma R_{t+1}$$$: sum of rewards at time t+1 but future rewards are discounted
================================================================================
Q learning algorithm using discounted factor
$$$\hat{Q}(s,a) \leftarrow r + \gamma max_{a'}\hat{Q}(s',a')$$$
================================================================================
But when agent is being there, agent is confused because there are 2 ones
This confusing can be resolved by "discounted reward"
================================================================================
"Discounted reward": discount reward which can be obtained in too far future
================================================================================
$$$\hat{Q}(s,a) \leftarrow r + \max_{a^{'}} \hat{Q}(s^{'},a^{'})$$$
r: reward after agent does "action a"
$$$\hat{Q}(s^{'},a^{'})$$$: Q value in future time
================================================================================
Let's discount future value by multiplying 0.9
$$$\hat{Q}(s,a) \leftarrow r + 0.9 \times \max_{a^{'}} \hat{Q}(s^{'},a^{'})$$$
================================================================================
$$$R=r_{1}+...+r_{n}$$$
$$$R_{t}=r_{t}+r_{t+1}+...+r_{n}$$$
$$$R$$$: sum of all rewards
$$$R_{t}$$$: sum of all rewards at time t
================================================================================
Discounted rewards
$$$R_{t}=r_{t}+\gamma r_{t+1}+\gamma^{2}r_{t+2}+...+\gamma^{n-t}r_{n}$$$
$$$r_{t}$$$: current reward (better than future reward )
$$$R_{t}=r_{t}+\gamma (r_{t+1}+\gamma(r_{t+2}+...))$$$
$$$R_{t}=r_{t}+\gamma R_{t+1}$$$
$$$\gamma R_{t+1}$$$: sum of rewards at time t+1 but future rewards are discounted
================================================================================
Q learning algorithm using discounted factor
$$$\hat{Q}(s,a) \leftarrow r + \gamma max_{a'}\hat{Q}(s',a')$$$
================================================================================
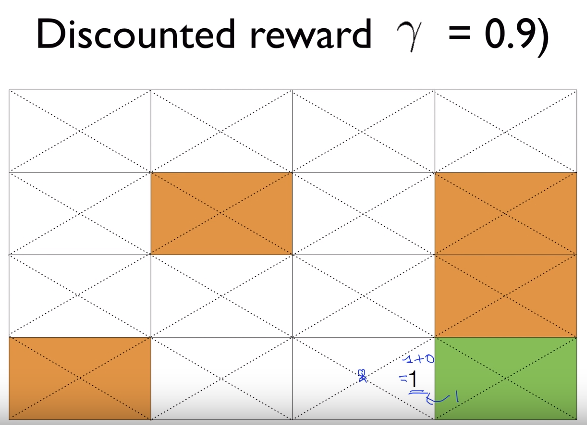 $$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=1+0.9\times 0$$$
$$$=1$$$
================================================================================
$$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=1+0.9\times 0$$$
$$$=1$$$
================================================================================
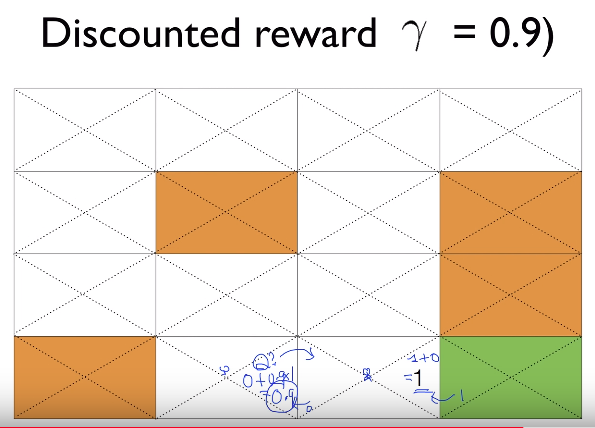 $$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=0+0.9\times 1$$$
$$$=0.9$$$
================================================================================
$$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=0+0.9\times 1$$$
$$$=0.9$$$
================================================================================
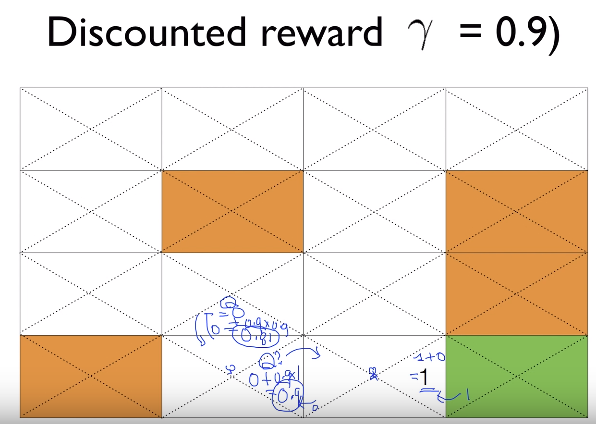 $$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=0+0.9\times 0.9$$$
$$$=0.81$$$
================================================================================
$$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=0+0.9\times 0.9$$$
$$$=0.81$$$
================================================================================
 $$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=0+0.9\times 1$$$
$$$=0.9$$$
================================================================================
$$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=0+0.9\times 1$$$
$$$=0.9$$$
================================================================================
 $$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=0+0.9\times 0.81$$$
$$$=0.729$$$
================================================================================
$$$Q$$$
$$$=\text{reward}+\gamma \times \text{maxQ}$$$
$$$=0+0.9\times 0.81$$$
$$$=0.729$$$
================================================================================
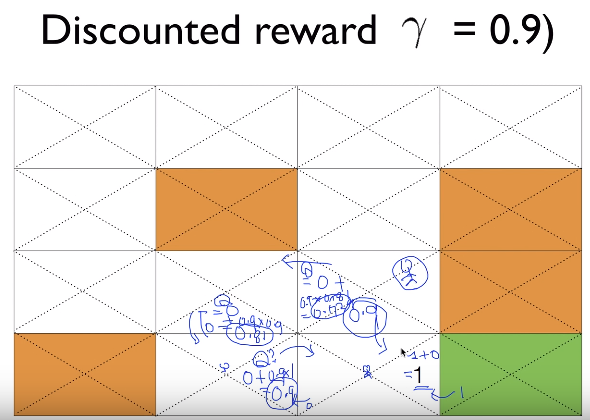 Suppose agent is in there
Agent will move down using 0.9
================================================================================
Suppose agent is in there
Agent will move down using 0.9
================================================================================