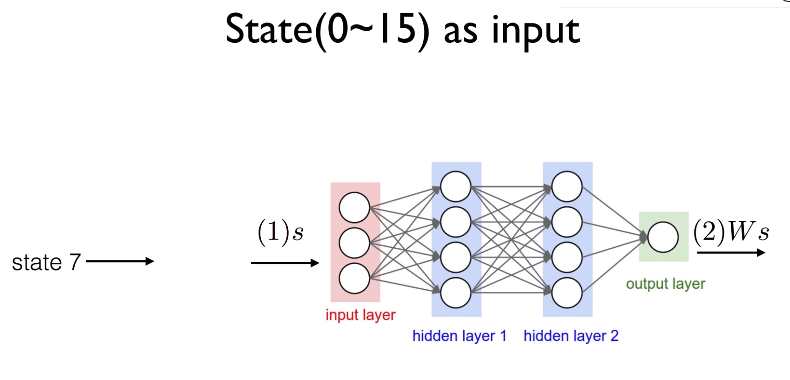




import gym import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # ================================================================================ # c env: stochastic (non-deterministic) environment env=gym.make('FrozenLake-v0') # ================================================================================ input_size=env.observation_space.n output_size=env.action_space.n # ================================================================================ learning_rate=0.1 # ================================================================================ # c X: placeholder for input X=tf.placeholder(shape=[1,input_size],dtype=tf.float32) # c W: Variable for trainable weight # 0,0.01 are for initialization W=tf.Variable(tf.random_uniform([input_size,output_size],0,0.01)) # ================================================================================ # c Qpred: is q values from $$$\hat{Q}$$$ function, # representing predictied probabilities for each action Qpred=tf.matmul(X,W) # ================================================================================ # c Y: is output representing each action as one hot vector Y=tf.placeholder(shape=[1,output_size],dtype=tf.float32) # ================================================================================ # Since it's matrix, you should use reduce_sum loss=tf.reduce_sum(tf.square(Y-Qpred)) train=tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(loss) # ================================================================================ dis=.99 num_episodes=2000 # ================================================================================ # You create list to save history of summed reward per episode rList=[] # ================================================================================ def one_hot(x): return np.identity(16)[x:x+1] # ================================================================================ init=tf.global_variables_initializer() # ================================================================================ with tf.Session() as sess: sess.run(init) ================================================================================ for i in range(num_episodes): s=env.reset() # Reset env per episode e=1./((i/50)+10) # For exploration rAll=0 done=False local_loss=[] ================================================================================ while not done: # Q-network training Qs=sess.run(Qpred,feed_dict={X:one_hot(s)}) if np.random.rand(1)<e: # Exploration a=env.action_space.sample() else: # Exploitation a=np.argmax(Qs) # ================================================================================ # Execute action and get data from env s1,reward,done,_=env.step(a) ================================================================================ if done: # If episode ended # you update reward in Q value Qs[0,a]=reward else: # If episode not ended # Q value at next state Qs1=sess.run(Qpred,feed_dict={X:one_hot(s1)}) Qs[0,a]=reward+dis*np.max(Qs1) # ================================================================================ # You train your network by using target Y and X (state) sess.run(train,feed_dict={X:one_hot(s),Y:Qs}) # ================================================================================ rAll+=reward s=s1 # ================================================================================ rList.append(rAll) # ================================================================================ print("Percent of successful episodes: "+str(sum(rList)/num_episodes)+"%") plt.bar(range(len(rList)),rList,color="blue") plt.show()